4장: 모델 훈련 part 2 (p.161)
경사 기울기 하강법
개요 : data들의 최적점은 기울기가 0인 곳(하나의 global minimum만 존재할 때)에 있고, 이는 각각의 data들을 정답에 대해 편미분 했을 때 연립방정식으로 0을 갖는 해를 가졌을 경우 해결된다. 하지만 이 과정은 linear independent해야 가능한데 이를 확인하는 것이 불가능에 가깝기 때문에 그 근처로 가려는 접근을 시도한다. 그 방법은 각 data들이 정답에 대해 편미분을 하면 기울기들이 나오는데 이 기울기를 0에 가깝게 조금씩 조금씩 학습시키는 것이다. 이 방법을 Gradient Descent Method라 한다.
Part 2. Gradient Descent
이 또한 다른 책을 공부할 때 다루었기 때문에 자세한 설명은 그림으로 대체한다.

평소 convex function에 대한 개념이 정확히 없어 정리한 것이다.

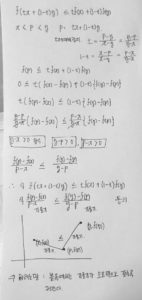
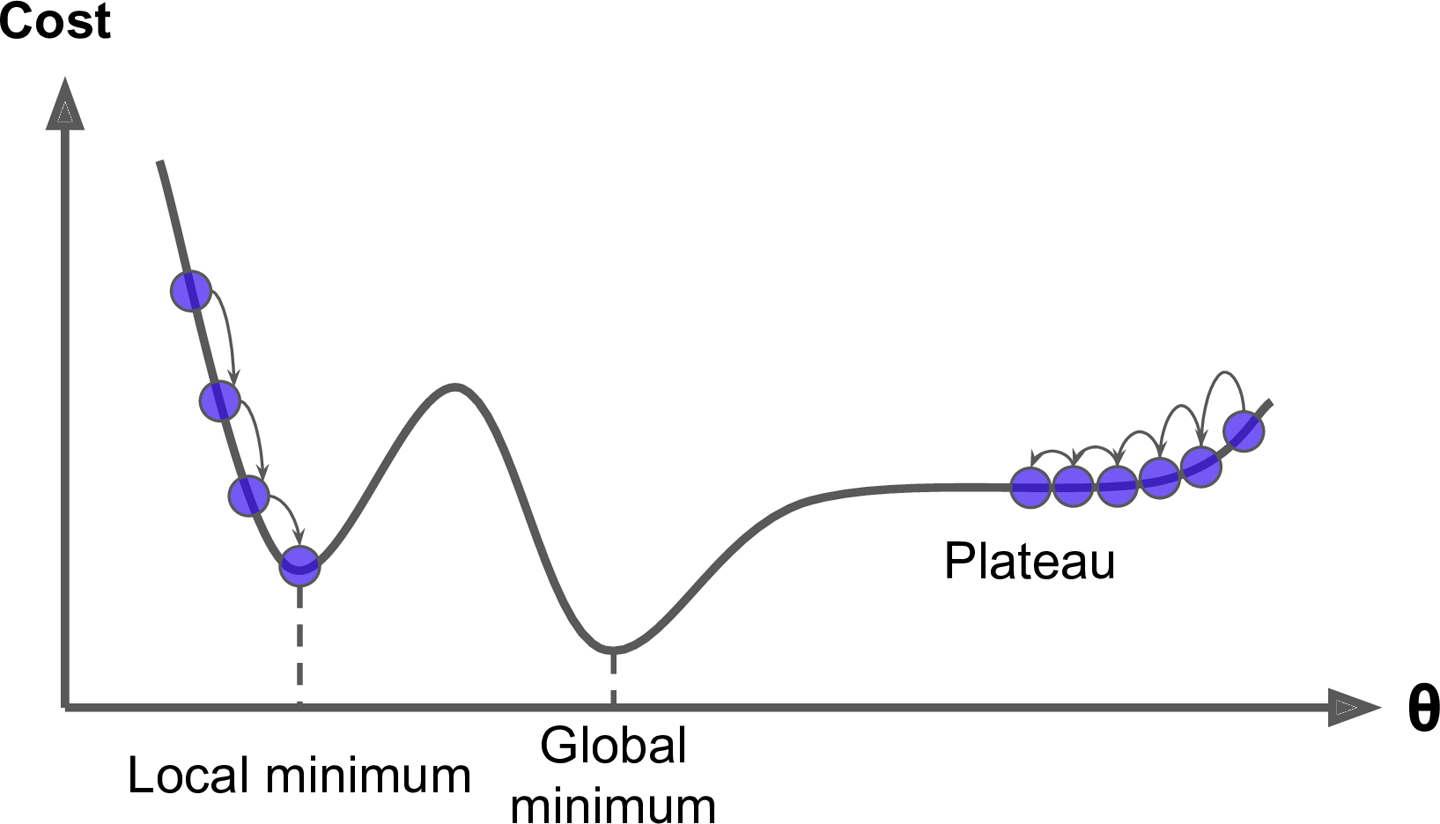
Linear Regression 에서 사용하는 MSE 비용함수 (자승 형태)는 convex function이다. 이는 Global minimum 하나만 존재하여 위처럼 local minimum에 빠질 위험이 없다는 뜻이다. 또는 연속된 함수이고 기울기가 갑자기 변하지 않는다. 이 두 사실로 부터 Gradient descent는 전역 최솟값에 가깝게 접근할 수 있다는 것이 보장된다.
Gradient Descent에서 특성 스케일이 필요한 이유

경사 하강법을 사용할 때는 반드시 모든 특성이 같은 스케일을 갖도록 만들어야한다. 그렇지 않으면 수렴하는 데 오래 걸린다.
Batch Gradient Descent
비용함수의 편도함수

이 공식은 매 경사 하강법 step 에서 전체 훈련세트 X에 대해 계산한다. 이를 Batch Gradient Descent라 한다. 그래서 큰 훈련 세트에서는 매우 느리다. 그러나 경사 하강법은 특성 수에 민감하지 않다. 수십만 개의 특성에서 선형 회귀를 훈련시키려면 정규방정식보다 경사 하강법을 사용하는 편이 훨씬 빠르다.
학습률 η는 하이퍼 파라미터로 사용자가 직접 정해야 하는 값이다. 보통 0.1 , 0.01을 많이 사용한다. 아래는 간단히 구현코드다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#Gradient Descent 알고리즘 eta = 0.1 n_iterations = 1000 m = 100 theta = np.random.randn(2,1) # 무작위 초기화 for iterations in range(n_iterations): gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y) theta = theta - eta * gradients print(theta) |
![]()
우연의 일치로 매우 정확하게 맞추었다. 다음은 세가지 다른 학습률을 사용하여 진행한 경사 하강법의 스텝 처음 10개를 보여준다.( 점선은 시작점을 나타낸다.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
theta_path_bgd = [] def plot_gradient_descent(theta, eta, theta_path=None): m = len(X_b) plt.plot(X, y, "b.") n_iterations = 1000 for iteration in range(n_iterations): if iteration < 10: y_predict = X_new_b.dot(theta) style = "b-" if iteration > 0 else "r--" plt.plot(X_new, y_predict, style) gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y) theta = theta - eta * gradients if theta_path is not None: theta_path.append(theta) plt.xlabel("$x_1$", fontsize=18) plt.axis([0, 2, 0, 15]) plt.title(r"$\eta = {}$".format(eta), fontsize=16) np.random.seed(42) theta = np.random.randn(2,1) # random initialization plt.figure(figsize=(10,4)) plt.subplot(131); plot_gradient_descent(theta, eta=0.02) plt.ylabel("$y$", rotation=0, fontsize=18) plt.subplot(132); plot_gradient_descent(theta, eta=0.1, theta_path=theta_path_bgd) plt.subplot(133); plot_gradient_descent(theta, eta=0.5) plt.show() |

학습률이 0.02 일때는 개미 똥만큼 움직이다가 끝나서 답에 도달하지 못했고 0.1 일때는 최적점을 잘 찾아간 반면 0.5 일 때는 건너편 동네까지 가버리는 상황이 발생한다.(divergence). 적절한 학습률을 찾으려면 그리드 탐색을 사용해보는 방법이 있다. 하지만 그리드 탐색에서 수렴하는 데 너무 오래 걸리는 모델을 막기 위해 반복 횟수를 제한해야 한다.
반복횟수를 아주 크게 하고 gradient vector가 아주 작아지면, 즉 벡터의 노름이 어떤 값 ɛ(허용 오차 tolerance) 보다 작아지면 Gradient descent 가 최솟 값에 거의 도달한 것이므로 알고리즘을 중지하는 것이다. (cost function 이 convex function이고 MSE같이 기울기가 급격하게 바뀌지 않는 경우 학습률을 고정한 배치 경사 하강법은 시간이 걸리겠지만 결국 수렴한다.)
Stochastic Gradient Descent
배치 경사 하강법과 다르게 확률적 경사 하강법은 딱 한 개의 샘플을 무작위로 선택하고 그 하나의 샘플에 대한 gradient를 계산한다. 이는 매우 빠르지만 variance가 상대적으로 커져 값이 불안정해진다.

위 그림처럼 최적점 지역에는 가겠으나 그 지역에서 제일 좋은 점(dot)은 확률적으로 머무르게 될 것이다. 또한 확률적이기 때문에 local minimum을 지나갈 수 있는 이점을 제공해줄 수 도있다. 이런 딜레마를 해결하는 한 가지 방법은 학습률을 점진적으로 감소시키는 것이 있다. (Ada grad) Deep Learning from scratch에 포스팅돼있음.
다음코드는 확률적 경사 하강법의 구현이다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#확률적 경사 하강법 theta_path_sgd = [] m = len(X_b) np.random.seed(42) n_epochs = 50 t0, t1 = 5,50 #학습 스케쥴 하이퍼파라미터 def learning_schedule(t): return t0 / (t + t1) theta = np.random.randn(2,1) for epoch in range(n_epochs): for i in range(m): if epoch == 0 and i < 20: y_predict = X_new_b.dot(theta) style = "b-" if i > 0 else "r--" plt.plot(X_new, y_predict, style) random_index = np.random.randint(m) #0~99까지 랜덤으로 숫자 선택 xi = X_b[random_index:random_index+1] #밑에 dot연산을 하기 위해 2차원으로 맞춰줌 yi = y[random_index:random_index+1] gradients = 2 * xi.T.dot(xi.dot(theta) - yi) eta = learning_schedule(epoch * m + i) #학습률을 조절한다. theta = theta - eta * gradients theta_path_sgd.append(theta) print(theta) plt.plot(X, y, "b.") plt.xlabel("$x_1$", fontsize=18) plt.ylabel("$y$", rotation=0, fontsize=18) plt.axis([0, 2, 0, 15]) plt.show() |
epoch = 50, m = 100 즉 5000번을 돌리는 for문으로 학습률을 조절하며 훈련하는 코드다. 훈련 후 결과는
![]() 매우 비슷하며 (이번건 매우 잘나옴)
매우 비슷하며 (이번건 매우 잘나옴)
훈련 step 의 첫 20개를 보면 다음과 같다.
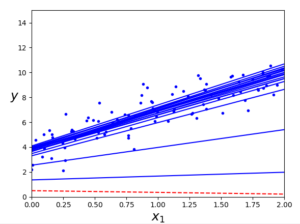
샘플을 무작위로 선택하기 때문에 어떤 샘플은 한 epoch에서 여러 번 선택될 수 있고 어떤 샘플은 전혀 선택되지 못할 수도 있다. epoch마다 모든 샘플을 사용하게 하려면 훈련 세트를 섞은 후 차례대로 하나씩 선택하고 다음 epoch에서 다시 섞는 식의 방법(SGDClassifier, SGDRegressor가 사용하는 방법)을 사용할 수 있으나 보통 더 늦게 수렴한다.
사이킷 런에서 SGD방식으로 선형 회귀를 사용하려면 기본 값으로 제곱 오차 비용 함수를 최적화화는 SGDRegressor클래스를 사용한다. 다음 코드는 학습률 0.1(eta0 = 0.1)로 기본 학습 스케줄을 사용해 에포크를 50번 수행한다. (규제는 사용하지 않는다)
|
1 2 3 4 |
#SGD사용 sgd_reg = SGDRegressor(max_iter=50, penalty=None, eta0=0.1) sgd_reg.fit(X,y.ravel()) print("SGD 절편:",sgd_reg.intercept_,"\nSGD 기울기",sgd_reg.coef_) |
![]()
Mini batch Gradient Descent method
미니배치라 부르는 임의의 작은 샘플에 대해 gradient를 계산한다. 특히 미니배치를 어느정도 크게 하면 이 알고리즘은 파라미터 공간에서 SGD보다 덜 불규칙하게 움직인다.

batch 와 SGD 사이에 mini batch는 적절한 수행을 한다. (시간,비용과 불안전함에서 오는 중간의 적절한 지점)
m = 훈련 샘플 수 n = 특성 수
