3장 : 다중 레이블 분류, 다중 출력 분류 (p.148)
다중 레이블 분류
개요 : 분류기가 샘플마다 여러 개의 클래스(답)를 출력해야 할 때가 있다. 예를 들어 얼굴 인식 분류기를 생각해보면 한 사진에 여러 사람이 있을 수 있다. 분류기가 앨리스, 밥, 찰리 세 얼굴을 인식하도록 훈련되었다고 가정하자. 만약 한 사진에 앨리스와 찰리가 있으면 분류기는 [1,0,1]을 출력해야 한다. 이처럼 여러개의 이진 레이블을 출력하는 분류시스템을 ‘다중 레이블 분류’ multilabel classification 시스템이라고 한다.
간단한 예시
|
1 2 3 4 5 6 7 |
#다중 레이블 분류 y_train_large = (y_train >= 7) y_train_odd = (y_train % 2 == 1) y_multilabel = np.c_[y_train_large, y_train_odd] #np.c_ 열로 합치는 것 knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_multilabel) |
이 코드는 두개의 타깃 레이블이 담긴 y_multilabel 배열을 만든다. 하나의 타깃은 y_train이 7과 같거나 큰값을 나타내고, 다른 하나의 타깃은 홀수를 나타낸다. 이런 두 타깃(홀수이면서 7과 같거나 큰 값)레이블을 KNN으로 훈련시킨 코드다.
|
1 |
print(knn_clf.predict([some_digit])) |
![]()
[some_digit] 은 숫자 5인데 예측을 보면 7과같거나 큰 조건에서는 False를 홀수 조건에서는 True를 출력 값으로 예측하면서 맞게 예측한 것을 볼 수 있다.
참고 : 다중 레이블 분류기능을 모든 분류기가 지원해주지는 않는다. 지원해주는 분류기(결정 트리, 랜덤포레스트, OneVsRestClassifier)
평가 방법
다중 레이블 분류기를 평가하는 방법은 프로젝트에 따라 많고 다양하다. 일반적으로 생각해보면 confusion matrix를 지표로 어떤 측정 기준을 잡고 평균 점수를 구한다. 여기서는 F1 Score를 구하고 간단하게 평균 점수를 계산한다.
|
1 2 3 4 |
#F1점수의 평균 ( 다중레이블 평가 방법 ) y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3, n_jobs=-1) #n_jobs = -1 은 컴퓨터의모든프로세스를 동원해 작업한다. print(f1_score(y_multilabel, y_train_knn_pred, average="macro")) |
돌리는데 시간이 많이 걸려서 책에 있는 점수 : 0.977
이 코드는 모든 레이블의 가중치가 같다고 가정한 것이다. 가중치를 두어야 합리적인 상황이면 간단한 방법은 레이블에 클래스의 지지도 (즉, 타깃 레이블에 속한 샘플 수)를 가중치로 주는 것이다. 이렇게 하는 코드는 average = “weighted”로 설정하면 된다.
다중 출력 분류
용어는 다중 출력 다중 클래스 분류 (multioutput-multiclass classification 또는 multioutput classification)라고 한다. 예를 들어 이미지 28 x 28 을 생각해보면 한 이미지는 784개의 다중 레이블을 갖고 있으며, 각 레이블은 여러 개의 값을 가진다 ( 0~ 255 픽셀 강도)
예시 : 이미지에서 노이즈 제거하기
MNIST 숫자 이미지처럼 숫자말고 주위 배경이 0인 깨끗한 이미지를 np.random.randint를 써서 noise 0~100까지 랜덤하게 분포하는 이미지들로 만들어 본다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#다중 출력 분류 (이미지에 노이즈 씌우기) noise = np.random.randint(0,100, (len(X_train), 784)) X_train_mod = X_train + noise noise = np.random.randint(0,100, (len(X_test), 784)) X_test_mod = X_test + noise y_train_mod = X_train y_test_mod = X_test some_index = 5500 plt.subplot(121); plot_digit(X_test_mod[some_index]) plt.subplot(122); plot_digit(y_test_mod[some_index]) plt.show() |

왼쪽이 노이즈가 낀 이미지, 오른쪽이 원본이다. 이제 분류기를 훈련시켜 이 이미지를 깨끗하게 만들어본다.
|
1 2 3 4 5 |
#분류기 훈련 knn_clf.fit(X_train_mod,y_train_mod) clear_digit = knn_clf.predict([X_test_mod[some_index]]) plot_digit(clear_digit) plt.show() |
훈련시킨 분류기로 노이즈가 낀 특정 이미지가 어떤 이미지인지 예측해봤는데
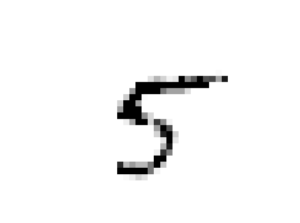 잘 예측했다.
잘 예측했다.
3장 전체 코드 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 |
from sklearn.datasets import fetch_mldata from sklearn.linear_model import SGDClassifier from sklearn.model_selection import cross_val_score from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_recall_curve from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.multiclass import OneVsOneClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import roc_auc_score from sklearn.metrics import roc_curve from sklearn.metrics import f1_score from sklearn.metrics import precision_score, recall_score from sklearn.metrics import confusion_matrix from sklearn.base import BaseEstimator from sklearn.base import clone import matplotlib import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl mnist = fetch_mldata('MNIST original') #print(mnist) X, y = mnist["data"], mnist["target"] #print(X.shape) #print(y.shape) #그림 확인해보기 some_digit = X[36000] #some_digit_image = some_digit.reshape(28,28) #plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, # interpolation="nearest") #plt.axis("off") #plt.show() #print(y[36000]) #데이터 분류 X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] shuffle_index = np.random.permutation(60000) X_train, y_train = X_train[shuffle_index], y_train[shuffle_index] #이진 분류기 훈련 #target vector making #y_train_5 = (y_train == 5) # 5는 True 나머지는 False #y_test_5 = (y_test == 5) #분류 모델 :SGD 사용 sgd_clf = SGDClassifier(max_iter=5, random_state=42) #sgd_clf.fit(X_train, y_train_5) #print(sgd_clf.predict([some_digit])) #교차 검증 구현 #skfolds = StratifiedKFold(n_splits= 3, random_state=42) #for train_index, test_index in skfolds.split(X_train,y_train_5): # clone_clf = clone(sgd_clf) # X_train_folds = X_train[train_index] # y_train_folds = y_train_5[train_index] # X_test_fold = X_train[test_index] # y_test_fold = y_train_5[test_index] # clone_clf.fit(X_train_folds, y_train_folds) # y_pred = clone_clf.predict(X_test_fold) # n_correct = sum(y_pred == y_test_fold) # print("교차검증 구현: ",n_correct / len(y_pred)) #print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")) #5아님 더미클래스 분류 후비교 class Never5Classifier(BaseEstimator): def fit(self,X, y=None): pass def predict(self,X): return np.zeros((len(X),1), dtype=bool) #never_5_clf = Never5Classifier() #print(cross_val_score(never_5_clf,X_train,y_train_5, cv=3, scoring="accuracy")) #오차 행렬 #y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) #print("오차행렬") #print(confusion_matrix(y_train_5,y_train_pred)) #완벽한 오차가 없는 행렬일 경우 #print(confusion_matrix(y_train_5,y_train_5)) #정밀도와 재현율 #print("정밀도 :",precision_score(y_train_5, y_train_pred)) #정밀도 #print("재현율 :",recall_score(y_train_5,y_train_pred)) #재현율 #F1 score (조화평균) #print("조화 평균 :", f1_score(y_train_5,y_train_pred)) #정밀도 재현율 trade - off #y_scores = sgd_clf.decision_function([some_digit]) #print(y_scores) #threshold = 0 #y_some_digit_pred = (y_scores > threshold) #print(y_some_digit_pred) #threshold = 200000 #y_some_digit_pred = (y_scores > threshold) #print(y_some_digit_pred) #결정 임계값에 대한 정밀도와 재현율 #y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,method="decision_function") #precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(thresholds, precisions[:-1], "b--", label="precision") plt.plot(thresholds, recalls[:-1], "g-", label = "recall") plt.xlabel("threshold") plt.legend(loc="center left") plt.ylim([0,1]) #plot_precision_recall_vs_threshold(precisions,recalls,thresholds) def plot_precision_vs_recall(precisions, recalls): plt.plot(recalls, precisions, "b-", linewidth=2) plt.xlabel("Recall", fontsize=16) plt.ylabel("Precision", fontsize=16) plt.axis([0, 1, 0, 1]) #plt.figure(figsize=(8, 6)) #plot_precision_vs_recall(precisions, recalls) #plt.show() #y_train_pred_90 = (y_scores > 70000) #print(precision_score(y_train_5,y_train_pred_90)) #print(recall_score(y_train_5,y_train_pred_90)) #ROC곡선 #fpr, tpr, thresholds = roc_curve(y_train_5,y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0,1],[0,1],'k--') plt.axis([0,1,0,1]) plt.xlabel("False positive rate") plt.ylabel("True positive rate") #plot_roc_curve(fpr,tpr) #plt.show() #print(roc_auc_score(y_train_5,y_scores)) #2개의 분류기를 ROC로 비교 #forest_clf = RandomForestClassifier(random_state=42) #랜덤포레스트는 decision_fun메서드가 없어 predict_proba 를사용 #y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,method="predict_proba") #y_scores_forest = y_probas_forest[:,1] #양성클래스에 대한 확률을 점수로 사용 #fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest) #plt.plot(fpr,tpr,"b:", label="SGD") #plot_roc_curve(fpr_forest,tpr_forest,"random_forest") #plt.legend(loc="lower right") #plt.show() #print(roc_auc_score(y_train_5,y_scores_forest)) #다중 분류 sgd_clf.fit(X_train,y_train) #print(sgd_clf.predict([some_digit])) # some_digit = 36000 some_digit_scores = sgd_clf.decision_function([some_digit]) #print(some_digit_scores) #print("some_digit점수중 가장 큰값 :",np.argmax(some_digit_scores)) #print("class 종류 : ",sgd_clf.classes_) #print("[5]인덱스 class :",sgd_clf.classes_[5]) #OvO OR OvA 선택해서 사용하기 #ovo_clf = OneVsOneClassifier(SGDClassifier(max_iter=5, random_state=42)) #ovo_clf.fit(X_train,y_train) #print("일대일을 사용한 sgd분류기의 예측 값:",ovo_clf.predict([some_digit])) #print("일대일 추정값 개수 :",len(ovo_clf.estimators_)) #forest_clf = RandomForestClassifier(random_state=42) #forest_clf.fit(X_train, y_train) #print(forest_clf.predict([some_digit])) #print(forest_clf.predict_proba([some_digit])) #분류기 평가 #print(cross_val_score(sgd_clf,X_train,y_train, cv=3, scoring="accuracy")) scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) #print(cross_val_score(sgd_clf, X_train_scaled,y_train, cv=3,scoring="accuracy")) #에러분석 #y_train_pred = cross_val_predict(sgd_clf,X_train_scaled, y_train, cv=3) #conf_mx = confusion_matrix(y_train,y_train_pred) #print(conf_mx) #plt.matshow(conf_mx, cmap=plt.cm.gray) #error 비율 보기 #row_sums = conf_mx.sum(axis=1, keepdims=True) # axis=1은 각행을 더한것,차원은유지 #norm_conf_mx = conf_mx / row_sums #np.fill_diagonal(norm_conf_mx, 0) #plt.matshow(norm_conf_mx, cmap=plt.cm.gray) #plt.show() #개개의 에러 #cl_a, cl_b = 3,5 #X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)] #X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)] #X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)] #X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)] def plot_digit(data): image = data.reshape(28, 28) plt.imshow(image, cmap = mpl.cm.binary, interpolation="nearest") plt.axis("off") def plot_digits(instances, images_per_row=10, **options): size = 28 images_per_row = min(len(instances), images_per_row) images = [instance.reshape(size,size) for instance in instances] n_rows = (len(instances) - 1) // images_per_row + 1 row_images = [] n_empty = n_rows * images_per_row - len(instances) images.append(np.zeros((size, size * n_empty))) for row in range(n_rows): rimages = images[row * images_per_row : (row + 1) * images_per_row] row_images.append(np.concatenate(rimages, axis=1)) image = np.concatenate(row_images, axis=0) plt.imshow(image, cmap = mpl.cm.binary, **options) plt.axis("off") #plt.figure(figsize=(8,8)) #plt.subplot(221); plot_digits(X_aa[:25], images_per_row=5) #plt.subplot(222); plot_digits(X_ab[:25], images_per_row=5) #plt.subplot(223); plot_digits(X_ba[:25], images_per_row=5) #plt.subplot(224); plot_digits(X_bb[:25], images_per_row=5) #plt.show() #다중 레이블 분류 y_train_large = (y_train >= 7) y_train_odd = (y_train % 2 == 1) y_multilabel = np.c_[y_train_large, y_train_odd] #np.c_ 열로 합치는 것 knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_multilabel) #print(knn_clf.predict([some_digit])) #F1점수의 평균 ( 다중레이블 평가 방법 ) #y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3, n_jobs=-1) #n_jobs = -1 은 컴퓨터의모든프로세스를 동원해 작업한다. #print(f1_score(y_multilabel, y_train_knn_pred, average="macro")) #다중 출력 분류 (이미지에 노이즈 씌우기) noise = np.random.randint(0,100, (len(X_train), 784)) X_train_mod = X_train + noise noise = np.random.randint(0,100, (len(X_test), 784)) X_test_mod = X_test + noise y_train_mod = X_train y_test_mod = X_test some_index = 5500 #plt.subplot(121); plot_digit(X_test_mod[some_index]) #plt.subplot(122); plot_digit(y_test_mod[some_index]) #분류기 훈련 knn_clf.fit(X_train_mod,y_train_mod) clear_digit = knn_clf.predict([X_test_mod[some_index]]) plot_digit(clear_digit) plt.show() |
References : Hands – On Machine Learning with Scikit Learn & TensorFlow