2장: 머신러닝프로젝트 처음부터 끝까지 (p.99)
1. 머신러닝 알고리즘을 위한 데이터 준비
머신러닝 알고리즘을 위해 데이터를 준비할 차례인데 이 작업을 함수로 만들어 자동화한다. (향후 편리함을 위하여)
먼저 원래 훈련세트로 복원(strat_train_set 다시한번 복사). 예측 변수와 타깃 값에 같은 변형을 적용하지 않기 위해 예측 변수와 레이블을 분리한다. (drop()은 복사본을 만들며 strat_train_set에 영향을 주지 않는다.)
|
1 2 3 |
#예측 변수와 레이블 분리 housing = strat_train_set.drop("median_house_value", axis=1) housing_labels = strat_train_set["median_house_value"].copy() |
데이터 정제
누락된 특성을 다루는 함수 몇개 정도 만든다. 앞서 total_bedrooms 특성 207개가 없던 것을 알 수 있다. 이 경우 다룰 수 있는 방법은 3가지다.
1.해당구역 제거
2.전체특성 삭제
3.어떤 값으로 채움 (0, 평균, 중간값 등)
|
1 2 3 4 5 |
#데이터 정제 housing.dropna(subset=["total_bedrooms"]) #옵션1 housing.drop("total_bedrooms", axis=1) #옵션2 median = housing["total_bedrooms"].median() #옵션3 housing["total_bedrooms"].fillna(median,inplace=True) |
dropna 함수는 Nan 값에 대해 삭제 해버리는 함수다. drop함수는 특정 열 또는 행을 삭제 하는 함수다. fillna는 특정 값으로 대체하는 함수다. 옵션 3을 이용하게 될 경우 훈련세트 중에서 중간 값(평균도 가능)을 계산하여 저장 후 이 값으로 처리해야 한다. Imputer 함수가 결측 값을 해당 값으로 대치해준다.
|
1 |
imputer = Imputer(strategy="median") |
median을 선택하여 중앙값을 대치값으로 결정했다. 또한 이값을 숫치적 특성에만 해당되기 때문에 앞서 보았던 텍스트 특성인 ocean_proximity를 제외한 데이터를 사용해야 한다.
|
1 2 3 |
#텍스트 제외한 데이터만들기 housing_num = housing.drop("ocean_proximity", axis=1) imputer.fit(housing_num) |
imputer 함수를 fit을 이용해 각 특성의 중간 값으로 Nan값을 대치시킨다. Nan값이 발견된 건 total_bedrooms 뿐이지만 전체를 해주는 이유는 나중에 서비스될 때 새로운 데이터에서 어떤 값이 누락될지 확실한 수 없으므로 모든 특성에 imputer를 적용한다.
|
1 2 |
print(imputer.statistics_) print(housing_num.median().values) |

imputer.statistics_는 각 속성의 중앙값을 계산하여 statistics_에 저장해놓는다.
|
1 |
X = imputer.transform(housing_num) |
이 결과는 변형된 특성들이 들어있는 numpy 형식 array이다. 이를 다시 pandas dataframe으로 되돌린다.
|
1 |
housing_tr = pd.DataFrame(X,columns=housing_num.columns, index= list(housing.index.values)) |
텍스트와 범주형 특성 다루기
앞서 범주형 특성 ocean_proximity가 텍스트다.
|
1 2 |
housing_cat = housing["ocean_proximity"] print(housing_cat.head(10)) |

대부분 머신러닝 알고리즘은 숫자형을 다루기 때문에 이도 마찬가지로 숫자형으로 변환해준다. 이를 위해 각 카테고리를 다른 정숫값으로 mapping 해주는 pandas의 factorize() 매서드를 이용한다.
|
1 2 |
housing_cat_encoded, housing_categories = housing_cat.factorize() print(housing_cat_encoded[:10]) |
![]() < 1H OCEAN : 0 , NEAR OCEAN : 1, INLAND : 2>
< 1H OCEAN : 0 , NEAR OCEAN : 1, INLAND : 2>
|
1 |
print(housing_categories) |
![]()
실제로 1H OCEAN (0)과 ISLAND(4)가 비슷하나 머신러닝은 0과 1처럼 가까이 있는 값이 더 비슷하다고 생각한다. 그래서 binomial하게 만들어서 해결해준다. 한 특징이 1이고 다른 특징이 0이 되게 해당하는 특성마다 그렇게 해주는 변환이 one-hot encoding 이라한다.
|
1 2 3 4 |
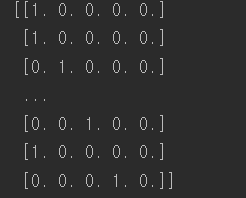
#one hot encode encoder = OneHotEncoder() housing_cat_1hot = encoder.fit_transform(housing_cat_encoded.reshape(-1,1)) print(housing_cat_1hot.toarray()) |
fit_transform은 2차원 배열을 넣어줘야 하는데 housing_cat_encoded는 1차원 배열이므로 구조를 reshape 해준다. 희소 행렬로 출력이 되는데 이는 수천 개의 카테고리가 있는 범주형 특성일 경우 매우 효율적이다. 이런 특성을 one_hot encoding 하면 열이 수천 개인 행렬로 변하고 각 행은 1이 하나뿐이고 그외에는 모두 0으로 채워질 것이다. 쓸데 없는 0을 저장하는건 낭비이므로 희소 행렬은 1의 위치만 저장한다. 밀집된 numpy array로 바꾸려면 toarray 메서드를 호출한다.
나만의 변환기 (파이프라인)
특별한 정제 작업이나 어떤 특성들을 조합하는 등의 작업을 위해 자신만의 변환기를 만들어야 할 때가 있다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#pipe line making rooms_ix, bedrooms_ix, population_ix, household_ix = 3,4,5,6 #keys인덱스값 class CombinedAttributesAdder(BaseEstimator, TransformerMixin): def __init__(self, add_bedrooms_per_room = True): #*args나 **kargs가 아님 self.add_bedrooms_per_room = add_bedrooms_per_room def fit(self, X, y=None): return self #더 할일 이없다. def transform(self, X, y=None): rooms_per_household = X[:, rooms_ix] / X[:, household_ix] population_per_household = X[:, population_ix] / X[:, household_ix] if self.add_bedrooms_per_room: bedrooms_per_room = X[:, bedrooms_ix] / X[:,rooms_ix] return np.c_[X, rooms_per_household, population_per_household,bedrooms_per_room] else: return np.c_[X, rooms_per_household, population_per_household] attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) housing_extra_attribs = attr_adder.transform(housing.values) |
이 경우에는 변환기가 add_bedrooms_per_room 하이퍼파라미터 하나를 가지고 있고 기본 값을 True로 지정한다. add_bedrooms_per_room이라는 변수를 내가 추가해서 머신러닝을 학습할지 안할지를 이 class로 쉽게 구현한다. 일반적으로 100% 확신이 없는 모든 데이터 준비 단계에 대해 하이퍼 파라미터를 추가할 수 있고 자동화할수록 더 많은 조합의 시도가 가능하고 가능성이높아진다.
특성 스케일링 Feature Scaling
머신러닝 알고리즘은 입력 숫자 특성들의 스케일이 많이 다르면 잘 작동하지 않는다. 예를들어 전체 방 갯수 범위가 6~39,320 이고 중간 소득의 범위는 0~ 15 이다. 모든 특성의 범위를 같도록 만들어주는 방법으로 min-max (정규화)스케일링, 표준화 가 있다.

(모든 변환기에서 스케일링은 (테스트 세트가 포함된) 전체 데이터가 아니고 훈련 데이터에 대해서만 fit()메서드를 적용해야 한다. 그런 다음 훈련세트와 테스트 세트( 그리고 새로운 데이터)에 대해 transform() 메서드를 사용한다.
변환파이프라인
변환단계가 많으며 정확한 순서대로 진행해야 하는데 이를 사이킷런에서 Pipeline 클래스가 도와준다. 다음은 숫자 특성을 처리하는 간단한 파이프라인이다.
|
1 2 3 4 5 6 7 8 |
#변환 파이프라인 num_pipeline = Pipeline([ ('imputer', Imputer(strategy="median")), ('attribs_adder', CombinedAttributesAdder()), ('std_scaler', StandardScaler()), ]) housing_num_tr = num_pipeline.fit_transform(housing_num) |
pipeline은 연속된 단계를 나타내는 이름/추정기 쌍의 목록을 입력으로 받는다. 마지막 단계에는 변환기와 추정기를 모두 사용할 수 있고 그 외에는 모든 변환기여야 한다.(fit_transform 메서드를 가지고 있어야한다.) fit() 메서드를 호출하면 모든 변환기의 fit_transform() 메서드를 순서대로 호출하여 한 단계의 출력을 입력으로 전달한다. 마지막 단계에서는 fit() 메서드만 호출.
업데이트 등 바뀐 전체 코드 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 |
from zlib import crc32 import matplotlib.font_manager as fm font_path ='C:\Windows\\Fonts\\NanumPen.ttf' fontprop = fm.FontProperties(fname=font_path, size=18) from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer import os import tarfile from six.moves import urllib import pandas as pd import csv import matplotlib.pyplot as plt import numpy as np from sklearn.model_selection import StratifiedShuffleSplit from pandas.plotting import scatter_matrix from sklearn.preprocessing import Imputer from sklearn.preprocessing import OneHotEncoder from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.base import BaseEstimator, TransformerMixin from sklearn.compose import ColumnTransformer from sklearn.utils import check_array from sklearn.preprocessing import LabelEncoder from scipy import sparse class CategoricalEncoder(BaseEstimator, TransformerMixin): """Encode categorical features as a numeric array. The input to this transformer should be a matrix of integers or strings, denoting the values taken on by categorical (discrete) features. The features can be encoded using a one-hot aka one-of-K scheme (``encoding='onehot'``, the default) or converted to ordinal integers (``encoding='ordinal'``). This encoding is needed for feeding categorical data to many scikit-learn estimators, notably linear models and SVMs with the standard kernels. Read more in the :ref:`User Guide <preprocessing_categorical_features>`. Parameters ---------- encoding : str, 'onehot', 'onehot-dense' or 'ordinal' The type of encoding to use (default is 'onehot'): - 'onehot': encode the features using a one-hot aka one-of-K scheme (or also called 'dummy' encoding). This creates a binary column for each category and returns a sparse matrix. - 'onehot-dense': the same as 'onehot' but returns a dense array instead of a sparse matrix. - 'ordinal': encode the features as ordinal integers. This results in a single column of integers (0 to n_categories - 1) per feature. categories : 'auto' or a list of lists/arrays of values. Categories (unique values) per feature: - 'auto' : Determine categories automatically from the training data. - list : ``categories[i]`` holds the categories expected in the ith column. The passed categories are sorted before encoding the data (used categories can be found in the ``categories_`` attribute). dtype : number type, default np.float64 Desired dtype of output. handle_unknown : 'error' (default) or 'ignore' Whether to raise an error or ignore if a unknown categorical feature is present during transform (default is to raise). When this is parameter is set to 'ignore' and an unknown category is encountered during transform, the resulting one-hot encoded columns for this feature will be all zeros. Ignoring unknown categories is not supported for ``encoding='ordinal'``. Attributes ---------- categories_ : list of arrays The categories of each feature determined during fitting. When categories were specified manually, this holds the sorted categories (in order corresponding with output of `transform`). Examples -------- Given a dataset with three features and two samples, we let the encoder find the maximum value per feature and transform the data to a binary one-hot encoding. >>> from sklearn.preprocessing import CategoricalEncoder >>> enc = CategoricalEncoder(handle_unknown='ignore') >>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) ... # doctest: +ELLIPSIS CategoricalEncoder(categories='auto', dtype=<... 'numpy.float64'>, encoding='onehot', handle_unknown='ignore') >>> enc.transform([[0, 1, 1], [1, 0, 4]]).toarray() array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.], [ 0., 1., 1., 0., 0., 0., 0., 0., 0.]]) See also -------- sklearn.preprocessing.OneHotEncoder : performs a one-hot encoding of integer ordinal features. The ``OneHotEncoder assumes`` that input features take on values in the range ``[0, max(feature)]`` instead of using the unique values. sklearn.feature_extraction.DictVectorizer : performs a one-hot encoding of dictionary items (also handles string-valued features). sklearn.feature_extraction.FeatureHasher : performs an approximate one-hot encoding of dictionary items or strings. """ def __init__(self, encoding='onehot', categories='auto', dtype=np.float64, handle_unknown='error'): self.encoding = encoding self.categories = categories self.dtype = dtype self.handle_unknown = handle_unknown def fit(self, X, y=None): """Fit the CategoricalEncoder to X. Parameters ---------- X : array-like, shape [n_samples, n_feature] The data to determine the categories of each feature. Returns ------- self """ if self.encoding not in ['onehot', 'onehot-dense', 'ordinal']: template = ("encoding should be either 'onehot', 'onehot-dense' " "or 'ordinal', got %s") raise ValueError(template % self.handle_unknown) if self.handle_unknown not in ['error', 'ignore']: template = ("handle_unknown should be either 'error' or " "'ignore', got %s") raise ValueError(template % self.handle_unknown) if self.encoding == 'ordinal' and self.handle_unknown == 'ignore': raise ValueError("handle_unknown='ignore' is not supported for" " encoding='ordinal'") X = check_array(X, dtype=np.object, accept_sparse='csc', copy=True) n_samples, n_features = X.shape self._label_encoders_ = [LabelEncoder() for _ in range(n_features)] for i in range(n_features): le = self._label_encoders_[i] Xi = X[:, i] if self.categories == 'auto': le.fit(Xi) else: valid_mask = np.in1d(Xi, self.categories[i]) if not np.all(valid_mask): if self.handle_unknown == 'error': diff = np.unique(Xi[~valid_mask]) msg = ("Found unknown categories {0} in column {1}" " during fit".format(diff, i)) raise ValueError(msg) le.classes_ = np.array(np.sort(self.categories[i])) self.categories_ = [le.classes_ for le in self._label_encoders_] return self def transform(self, X): """Transform X using one-hot encoding. Parameters ---------- X : array-like, shape [n_samples, n_features] The data to encode. Returns ------- X_out : sparse matrix or a 2-d array Transformed input. """ X = check_array(X, accept_sparse='csc', dtype=np.object, copy=True) n_samples, n_features = X.shape X_int = np.zeros_like(X, dtype=np.int) X_mask = np.ones_like(X, dtype=np.bool) for i in range(n_features): valid_mask = np.in1d(X[:, i], self.categories_[i]) if not np.all(valid_mask): if self.handle_unknown == 'error': diff = np.unique(X[~valid_mask, i]) msg = ("Found unknown categories {0} in column {1}" " during transform".format(diff, i)) raise ValueError(msg) else: # Set the problematic rows to an acceptable value and # continue `The rows are marked `X_mask` and will be # removed later. X_mask[:, i] = valid_mask X[:, i][~valid_mask] = self.categories_[i][0] X_int[:, i] = self._label_encoders_[i].transform(X[:, i]) if self.encoding == 'ordinal': return X_int.astype(self.dtype, copy=False) mask = X_mask.ravel() n_values = [cats.shape[0] for cats in self.categories_] n_values = np.array([0] + n_values) indices = np.cumsum(n_values) column_indices = (X_int + indices[:-1]).ravel()[mask] row_indices = np.repeat(np.arange(n_samples, dtype=np.int32), n_features)[mask] data = np.ones(n_samples * n_features)[mask] out = sparse.csc_matrix((data, (row_indices, column_indices)), shape=(n_samples, indices[-1]), dtype=self.dtype).tocsr() if self.encoding == 'onehot-dense': return out.toarray() else: return out #데이터 읽어들이기 # df = pd.read_csv('housing.csv',names=['longitude','latitude','housing_median_age','total_rooms', # 'total_bedrooms','population','households','median_income', # 'median_house_value','ocean_proximity']) housing = pd.read_csv('housing.csv') # 데이터 형태 훓어보기 #print(housing.head()) #print(housing.info()) #print(housing["ocean_proximity"].value_counts()) #print(housing.describe()) #housing.hist(bins=50, figsize=(20,15)) #plt.show() # 테스트 세트 만들기 #def split_train_test(data, test_ratio): # shuffled_indices = np.random.permutation(len(data)) # test_set_size = int(len(data) * test_ratio) # test_indices = shuffled_indices[ :test_set_size] # train_indices = shuffled_indices[test_set_size: ] # return data.iloc[train_indices], data.iloc[test_indices] #train_set, test_set = split_train_test(housing,0.2) #print("train 개수: "+ str(len(train_set)) + "\ttest 개수: "+str(len(test_set))) # 해시값을 이용한 테스트 세트 중복피하기 #def test_set_check(identifier, test_ratio): # return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32 #def split_train_test_by_id(data, test_ratio, id_column): # ids = data[id_column] # in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio)) # return data.loc[~in_test_set], data.loc[in_test_set] #housing_with_id = housing.reset_index() # 'index' 열이 추가된 데이터 프레임이 반환된다. #train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index") #housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"] #train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id") #sklearn 사용하여 나누기 train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42) #중간소득을 discrete하게 만들어주는 작업 housing["income_cat"] = np.ceil(housing["median_income"] / 1.5) housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True) #housing["income_cat"].hist(bins=50, figsize=(20,15)) #plt.show() #카테고리 기반 계층 샘플링 split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index] #print(housing["income_cat"].value_counts() / len(housing)) #print(housing["income_cat"].value_counts()) #income_cat 특성삭제 데이터를 원상태로 되돌림 for set_ in (strat_train_set, strat_test_set): set_.drop("income_cat", axis=1, inplace=True) #복사본 만들기 housing = strat_train_set.copy() #지리적 데이터 시각화 #housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4, # s=housing["population"]/100, label="population", figsize=(10,7), # c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True, sharex=False) #plt.xlabel('경도', fontproperties=fontprop) #plt.ylabel('위도', fontproperties=fontprop) #plt.show() #상관계수조사 #corr_matrix = housing.corr() #print(corr_matrix["median_house_value"].sort_values(ascending=False)) #각각 특성 그려보기 #attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"] #scatter_matrix(housing[attributes], figsize=(12,8)) #중간소득으로 중간주택가격 비교그래프 #housing.plot(kind="scatter", x="median_income", y="median_house_value", alpha=0.1) #plt.xlabel('중간소득', fontproperties=fontprop) #plt.ylabel('중간주택가격', fontproperties=fontprop) #plt.show() #특성조합 housing["rooms_per_household"] = housing["total_rooms"] / housing["households"] housing["bedrooms_per_room"] = housing["total_bedrooms"] / housing["total_rooms"] housing["population_per_household"] = housing["population"] / housing["households"] #corr_matrix = housing.corr() #print(corr_matrix["median_house_value"].sort_values(ascending=False)) #예측 변수와 레이블 분리 housing = strat_train_set.drop("median_house_value", axis=1) housing_labels = strat_train_set["median_house_value"].copy() #데이터 정제 housing.dropna(subset=["total_bedrooms"]) #옵션1 housing.drop("total_bedrooms", axis=1) #옵션2 median = housing["total_bedrooms"].median() #옵션3 housing["total_bedrooms"].fillna(median,inplace=True) imputer = Imputer(strategy="median") #텍스트 제외한 데이터만들기 housing_num = housing.drop("ocean_proximity", axis=1) imputer.fit(housing_num) #print(imputer.statistics_) #print(housing_num.median().values) X = imputer.transform(housing_num) housing_tr = pd.DataFrame(X,columns=housing_num.columns, index= list(housing.index.values)) #텍스트와 범주형 특성 다루기 housing_cat = housing["ocean_proximity"] #print(housing_cat.head(10)) housing_cat_encoded, housing_categories = housing_cat.factorize() #print(housing_cat_encoded[:10]) #print(housing_categories) #one hot encode encoder = OneHotEncoder() housing_cat_1hot = encoder.fit_transform(housing_cat_encoded.reshape(-1,1)) #print(housing_cat_1hot.toarray()) from sklearn.preprocessing import OneHotEncoder cat_encoder = OneHotEncoder(categories='auto') housing_cat_reshaped = housing_cat.values.reshape(-1, 1) housing_cat_1hot = cat_encoder.fit_transform(housing_cat_reshaped) housing_cat_1hot cat_encoder = OneHotEncoder(categories='auto', sparse=False) housing_cat_1hot = cat_encoder.fit_transform(housing_cat_reshaped) housing_cat = housing[['ocean_proximity']] from sklearn.preprocessing import OrdinalEncoder ordinal_encoder = OrdinalEncoder() housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat) from sklearn.preprocessing import OneHotEncoder cat_encoder = OneHotEncoder(categories='auto') housing_cat_1hot = cat_encoder.fit_transform(housing_cat) cat_encoder = OneHotEncoder(categories='auto', sparse=False) housing_cat_1hot = cat_encoder.fit_transform(housing_cat) #pipe line making rooms_ix, bedrooms_ix, population_ix, household_ix = 3,4,5,6 class CombinedAttributesAdder(BaseEstimator, TransformerMixin): def __init__(self, add_bedrooms_per_room = True): #*args나 **kargs가 아님 self.add_bedrooms_per_room = add_bedrooms_per_room def fit(self, X, y=None): return self #더 할일 이없다. def transform(self, X, y=None): rooms_per_household = X[:, rooms_ix] / X[:, household_ix] population_per_household = X[:, population_ix] / X[:, household_ix] if self.add_bedrooms_per_room: bedrooms_per_room = X[:, bedrooms_ix] / X[:,rooms_ix] return np.c_[X, rooms_per_household, population_per_household,bedrooms_per_room] else: return np.c_[X, rooms_per_household, population_per_household] attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) housing_extra_attribs = attr_adder.transform(housing.values) #변환 파이프라인 num_pipeline = Pipeline([ ('imputer', Imputer(strategy="median")), ('attribs_adder', CombinedAttributesAdder()), ('std_scaler', StandardScaler()), ]) housing_num_tr = num_pipeline.fit_transform(housing_num) num_attribs = list(housing_num) cat_attribs = ["ocean_proximity"] full_pipeline = ColumnTransformer([ ("num", num_pipeline, num_attribs), ("cat", OneHotEncoder(categories='auto'), cat_attribs), ]) #데이터프레임으로 변환시켜주는 변환기 class DataFrameSelector(BaseEstimator, TransformerMixin): def __init__(self, attribute_names): self.attribute_names = attribute_names def fit(self, X, y=None): return self def transform(self,X): return X[self.attribute_names].values num_attribs = list(housing_num) cat_attribs = ["ocean_proximity"] num_pipeline = Pipeline([ ('selector', DataFrameSelector(num_attribs)), ('imputer', SimpleImputer(strategy="median")), ('attribs_adder', CombinedAttributesAdder()), ('std_scaler', StandardScaler()), ]) cat_pipeline = Pipeline([ ('selector', DataFrameSelector(cat_attribs)), ('cat_encoder', CategoricalEncoder(encoding="onehot-dense")), ]) full_pipeline = ColumnTransformer([ ("num_pipeline", num_pipeline, num_attribs), ("cat_encoder", OneHotEncoder(categories='auto'), cat_attribs), ]) housing_prepared = full_pipeline.fit_transform(housing) print(housing_prepared) |
References : Hands-On Machine Learning with Scikit-Learn & Tensorflow