Machine learning에서 왜 MSE 보다 Cross-entropy를 더 많이 사용하는가?
Machine Learning 에서 흔히 Cost function으로써 MSE(mean squared error) 를 사용하지 않고 Cross-entropy를 사용하는 이유에 대해 생각해볼 필요가 있다.
문제의 정의 : Cross-entropy의 어떤 성질이 MSE의 부족한 어떤 점을 잘 cover해주기 때문이다 라고 생각
문제를 해결하기 위해 필요한 사전지식:
- MSE(mean squared error) 에 대한 이해
- Cross-entropy 에 대한 이해
- Machine Learning에서 사용하는 문제의 특징
문제 논의에 앞서 MSE 는 전 포스팅을 참고, 정보이론에 대해서 보다 자세하게 공부해봤다.
Information theory
self-information 과 entropy 의 정의
self-information은 확률의 역수에 -(마이너스)를 취한 것.
entropy는 기대치다.

Kull back Leibler divergence 정의 , 설명



과연 기대치만으로 두 분포가 같다고 할 수 있는가
Conditional Entropy, Joint Entropy, Bayes’ rule Entropy




Cross Entropy




KL divergence 보다 Cross entropy를 사용하는 이유:

Softmax with Cross entropy backporb 과정:
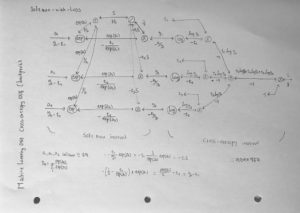
결론

MSE 는 추정치인 b^hat 가 명시적인 해인 (X’X)^-1 X’Y 를 가진다. 이 해를 보면 Y를 포함하는 항인데 이는 Y가 discrete한 데이터형태를 취할 경우 미분 개념에 올바르지 않기에 사용에 문제가 있다.
반면 Cross Entropy는 label 이 discrete 하더라도 영향을 받지 않으며 위의 내용처럼 수식 또한 코딩으로 구현하기 쉬워 선호된다.