1. 텍스트 다루기
앞으로 관심있어 해볼 RNN 에 대한 분야는 sequence 형태의 데이터들을 다루는데 효과적이다. RNN을 배우기 앞서 RNN에 쓰일 데이터들이 어떻게 생겨먹었는지와 개념 등을 익히는 것이 필요하다.
텍스트 데이터
먼저 sequence 데이터의 대표주자는 텍스트라고 할 수 있다. 텍스트 원본을 컴퓨터에서 직접 처리할 수 없으니 바꿔주는 작업을 거치는데 (수치형 텐서로) 이 과정을 vectorizing text 라고 한다. 이 방식에는 3가지가 있다.
- 텍스트를 단어로 나누고 각 단어를 하나의 벡터로 변환
- 텍스트를 문자로 나누고 각 문자를 하나의 벡터로 변환
- 텍스트에서 n-gram을 추출하여 각 n-gram을 하나의 벡터로 변환, n-gram은 연속된 단어나 문자의 그룹으로 텍스트에서 단어나 문자를 하나씩 이동하면서 추출한다.
n-gram이란 ? : 입력한 문자열을 n개의 기준단위로 절단하는 방법
ex ) “I am happy” 를 문자 절단 단위의 3-gram : “I_a”, “_am”, “am_”, “m_h”, “_ha”, “hap”, “app”, “ppy” 가 된다. 단어 단위 2-gram으로 나누게 된다면 “I am”, “am happy” 가 된다.
BoW란? 위의 집합을 각각 bag of 3-gram, bag of 2-gram이라 한다. bag이란 용어는 다루고자 하는 것이 리스트나 시퀀스가 아니라 토큰의 집합이라는 사실을 의미한다. 이 토큰은 특정한 순서가 없으며 이러 종류의 토큰화 방법을 BoW(Bag-of-Words)라 한다. BoW는 순서가 없는 토큰화 방법이기 때문에 문장의 일반적인 구조가 사라진다. 그래서 딥러닝 모델보다 얕은 학습 방법의 언어 처리 모델에 사용되는 경향이 있다.
이를 python으로 구현해본다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
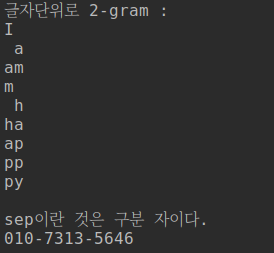
import numpy as np text = "I am happy" print("글자단위로 2-gram :") for i in range(len(text) - 1): print(text[i], text[i+1], sep='') print("") print("sep이란 것은 구분 자이다.") print('010' , '7313', '5646', sep='-') print("") print("단어 단위로 3-gram : ") text = "this is python script" #split은 공백을 기준으로 나누는 함수 words = text.split() print("split 함수로 나눈 text:", words) for i in range(len(words) - 2): print(words[i], words[i+1], words[i+2]) |

zip함수로 구현:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
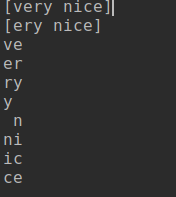
text = "very nice" two_gram = list(zip(text, text[1:])) print("[very nice]") print("[ery nice]") for i in two_gram: print(i[0], i[1], sep='') print("") test = "my mind is hard" test = test.split() test = list(zip(test, test[1:])) for i in test: print(i[0], i[1], sep='') |

단어와 문자의 원핫인코딩
텍스트를 나누는 이런 단위를 token 이라 하고 이런 과정을 tokenization이라 한다. 이런 벡터는 시퀀스 텐서로 묶여져서 심층 신경망에 주입된다. 토큰과 벡터를 연결하는 여러가지 방법 중에 one-hot encoding과 token embedding(word embedding) 를 알아본다.
단어 수준의 원 핫 인코딩을 할때 코드 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
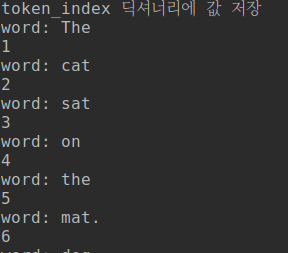
#단어 수준의 one_hot encoding samples = ['The cat sat on the mat.', 'The dog ate my homework.'] token_index = {} print("token_index 딕셔너리에 값 저장") for sample in samples: for word in sample.split(): #not in을 사용하는 이유는 단어마다 고유의 인덱스를 부여하기 위함. if word not in token_index: print("word:",word) token_index[word] = len(token_index) + 1 print(token_index[word]) print("저장된 딕셔너리 : ",token_index) max_length = 10 results = np.zeros(shape=(len(samples), max_length, max(token_index.values()) + 1)) print(np.shape(results)) #print(results) for i, sample in enumerate(samples): for j, word in list(enumerate(sample.split()))[:max_length]: index = token_index.get(word) results[i,j, index] = 1. print("\n") print(results) |
![]()
![]()
만들어진 딕셔너리를 가지고 원핫 인코딩을 하기 위해 results 를 0으로 채운 (2, 10 11) shape을 만든다.
![]()
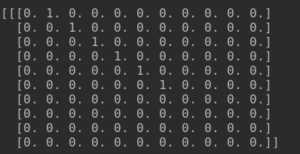 “The cat sat on the mat.” 이라는 문장을 원핫인코딩한결과
“The cat sat on the mat.” 이라는 문장을 원핫인코딩한결과
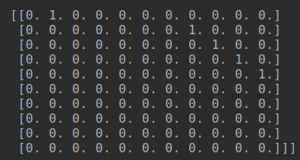 “The dog ate my homework.” 이라는 문장을 원핫인코딩한 결과
“The dog ate my homework.” 이라는 문장을 원핫인코딩한 결과
이번엔 문자 수준 원-핫 인코딩 코드:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#문자 수준 원-핫 인코딩 import string samples = ['The cat sat on the mat.', 'The dog ate my homework.'] characters = string.printable #출력가능한 모든 아스키문자 print("출력가능한 모든 아스키문자 :",characters) print("그 길이 :",len(characters)) token_index = dict(zip(characters, range(1, len(characters) + 1 ))) print(token_index) #print(len('The cat sat on the mat. The dog ate my homework.')) #print(max(token_index.values()) + 1) max_length = 50 results = np.zeros((len(samples), max_length, max(token_index.values()) + 1 )) b = token_index.get('T') #print(results.shape) for i, sample in enumerate(samples): for j, characters in enumerate(sample): index = token_index.get(characters) results[i,j, index] = 1. print(results) |

케라스를 사용한 단어 수준의 원-핫 인코딩 코드:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#케라스를 사용한 단어 수준의 원-핫 인코딩 from keras.preprocessing.text import Tokenizer samples = ['The cat sat on the mat.', 'The dog ate my homework.'] #가장 빈도가 높은 단어 1000개만 지정 tokenizer = Tokenizer(num_words=1000) tokenizer.fit_on_texts(samples) #단어 인덱스 구축 sequences = tokenizer.texts_to_sequences(samples) #문자열을 정수 인덱스 리스트로 변환 print("정수 인덱스로 반환된 문자열 :",sequences) #직접 원-핫 이진 벡터표현을 얻을 수 있다. 기타 많은 벡터화 방법들 제공. one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary') word_index = tokenizer.word_index #계산된 단어 인덱스를 구한다. print('%s개의 고유한 토큰을 찾았습니다.' % len(word_index)) print(one_hot_results.shape) print(one_hot_results) |
![]()
케라스에는 원본 텍스트 데이터를 단어 또는 문자 수준의 원핫 인코딩으로 변환해주는 유틸리티가 있다. 코드 부가 설명은 위에 있다. python으로 구현한 results 크기는 (samples, max_length, token_length + 1) 이지만 케라스로 구현한 results의 크기는 (samples, max_length) 이다.
원핫 인코딩의 변종 중 하나로 원-핫 해싱이 있는데 이 방식은 어휘 사전에 있는 고유한 토큰의 수가 너무 커서 모두 다루기 어려울 때 사용한다. 단어를 해싱하여 고정된 크기의 벡터로 변환한다. 이는 위의 코드와는 다르게 명시적인 인덱스가 필요 없어서 메모리를 절약하고 온라인 방식으로 데이터를 인코딩할 수 있다. 문제는 hash collision(해시 충돌)인데 2개의 단어가 같은 해시를 만들면 모델은 이 차이를 구분하지 못한다. so 해싱 공간의 차원을 해싱될 고유 토큰 전체 개수보다 크게하여 충돌 가능성을 감소시킨다.
해싱 기법을 사용한 단어 수준의 원-핫 인코딩 코드 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from keras.preprocessing.text import Tokenizer samples = ['The cat sat on the mat.', 'The dog ate my homework.'] #단어를 크기가 1000인 벡터로 저장한다. 1000개 이상의 단어가 있다면 해싱충돌이 늘어난다. dimensionality = 1000 max_length = 10 results = np.zeros((len(samples), max_length, dimensionality)) for i, sample in enumerate(samples): for j, word in list(enumerate(sample.split()))[:max_length]: #단어를 hash하여 절대값으로 바꾼뒤 1000으로 나눈 나머지 index = abs(hash(word)) % dimensionality print(index,word) results[i,j,index] = 1. |
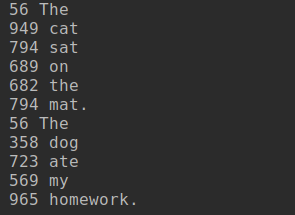 고유한 토큰 수가 너무 많을 때 일일이 지정이 어려우니 해시값으로 넘겨버림.
고유한 토큰 수가 너무 많을 때 일일이 지정이 어려우니 해시값으로 넘겨버림.
단어 임베딩:
개요설명///
|
1 2 3 4 5 6 |
#Embeddng층의 객체 생성하기 from keras.layers import Embedding #여기서 1000으로 단어 인덱스 최대값 + 1이다. 0은 사용안하기 때문 #임베딩 차원은 64 embedding_layer = Embedding(1000,64) |