10장: 조기종료 구현
Early Stopping 방법의 구현 :
구현 코드 : ( 모르는 함수와 부분에 대해 하나씩 따져본다.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 |
import numpy as np import tensorflow as tf import mnist import os import time def reset_graph(seed=42): tf.reset_default_graph() tf.set_random_seed(seed) np.random.seed(seed) #data setting ----------------------------------- (X_train, y_train), (X_test, y_test) = mnist.load_mnist(normalize=True) y_train = y_train.astype(np.int32) y_test = y_test.astype(np.int32) X_valid, X_train = X_train[:5000], X_train[5000:] y_valid, y_train = y_train[:5000], y_train[5000:] #------------------------------------------------ #층깊이 n_inputs = 28 * 28 n_hidden1 = 300 n_hidden2 = 100 n_outputs = 10 reset_graph() X = tf.placeholder(tf.float32, shape=(None,n_inputs), name="X") y = tf.placeholder(tf.int32, shape=(None), name="y") #tf.layers.dense를 이용해 신경망 층구현 with tf.name_scope("dnn"): he_init = tf.contrib.layers.variance_scaling_initializer() hidden1 = tf.layers.dense(X,n_hidden1, activation=tf.nn.relu, kernel_initializer=he_init, name="hidden1") hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, kernel_initializer=he_init, name="hidden2") logits = tf.layers.dense(hidden2,n_outputs, name="outputs") y_proba = tf.nn.softmax(logits) #loss 값 구하는 연산 with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y) loss = tf.reduce_mean(xentropy , name="loss") loss_summary = tf.summary.scalar("log_loss",loss) #훈련 연산 learning_rate = 0.01 with tf.name_scope("train"): optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate) training_op = optimizer.minimize(loss) #평가 연산 with tf.name_scope("eval"): correct = tf.nn.in_top_k(logits,y,1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) accuracy_summary = tf.summary.scalar("accuracy",accuracy) init = tf.global_variables_initializer() saver = tf.train.Saver() m,n = X_train.shape # m = 55000 , n = 784 #mini_batch하려고 def shuffle_batch(X, y, batch_size): rnd_idx = np.random.permutation(len(X)) #예를들어 55000개 n_batches = len(X) // batch_size #len(X)는 X의 행데이터 1100 for batch_idx in np.array_split(rnd_idx, n_batches): X_batch, y_batch = X[batch_idx], y[batch_idx] yield X_batch, y_batch n_epochs = 10001 batch_size = 50 n_batces = int(np.ceil(m/batch_size)) checkpoint_path = "C:\\Users\\고영민\\workspace\\parametersave\\my_deep_mnist_model.ckpt" checkpoint_epoch_path = checkpoint_path + ".epoch" final_model_path = "C:\\Users\\고영민\\workspace\\parametersave\\my_deep_mnist_model" best_loss = np.infty #무한대값 저장 epochs_without_progress = 0 max_epochs_without_progress = 50 """ with tf.Session() as sess: if os.path.isfile(checkpoint_epoch_path): #os.path.isfile : True,False # if the checkpoint file exists, restore the model and load the epoch number with open(checkpoint_epoch_path, "rb") as f: #이진파일 읽기 start_epoch = int(f.read()) print("Training was interrupted. Continuing at epoch", start_epoch) saver.restore(sess, checkpoint_path) else: start_epoch = 0 sess.run(init) start_time = time.time() for epoch in range(start_epoch, n_epochs): for X_batch, y_batch in shuffle_batch(X_train,y_train, batch_size): sess.run(training_op, feed_dict={X:X_batch, y:y_batch}) accuracy_val, loss_val = sess.run([accuracy, loss], feed_dict={X:X_valid, y:y_valid}) if epoch % 5 == 0: print("Epoch: ",epoch, "\tValidation accuracy: {:.3f}%".format(accuracy_val * 100), "\tLoss : {:.5f}".format(loss_val)) saver.save(sess, checkpoint_path) with open(checkpoint_epoch_path,"wb") as f: f.write(b"%d" % (epoch + 1)) if loss_val < best_loss: saver.save(sess,final_model_path) best_loss = loss_val else: epochs_without_progress += 5 if epochs_without_progress > max_epochs_without_progress: print("Early Stopping") break end_time = time.time() during_time = end_time - start_time print("걸린시간 : ",round(during_time,2)) """ os.remove(checkpoint_epoch_path) with tf.Session() as sess: saver.restore(sess, final_model_path) accuracy_val = accuracy.eval( feed_dict={X:X_test, y: y_test}) print(accuracy_val) |
result :
 training
training
![]() test accuracy
test accuracy
이 코드의 핵심은 epochs_without_progress 가 loss_val > best_loss 인 경우(즉 loss값이 진전이 없는 경우) += 5씩 증가하여 max 값인 50 을 초과하는 경우 (즉 11번동안 진전이 없을 경우) 조기종료한다. 여기서 문제는 진전이 없는 구간이 local minimum인 경우 최적해가 아니기 때문에 문제가 있으나 위의 예제에서는 해당하지 않는다.
with tf.name_scope(“dnn”): 에서 모르는 것:
- tf.contrib.layers.variance_scaling_initializer()
- tf.layers.dense()
1. tf.contrib.layers.variance_scaling_initializer(factor=2.0, mode=’FAN_IN’, uniform=False, seed=None, dtype=tf.float32)
분산을 스케일링하지 않고 텐서를 생성하는 initializer를 반환한다. 깊은 신경망을 초기화할 때 입력 분산의 스케일을 일정하게 유지하는 것이 원칙적으로 유리하므로 최종 레이어에 도달하여 폭발하거나 감소하지 않는다. 다음 수식을 따른다. (즉, initializer(단위 분산을 가진)를 반환하는 함수)
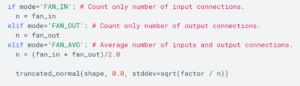
FAN_IN : 층의 입력 개수
FAN_OUT : 층의 출력 개수
FAN_AVG : 층의 입출력 합을 2로 나눈 것
의 3가지 mode를 가지고 있고 FAN_IN이 기본 값이다. ( n )
truncated_normal(shape, 0.0 , stddev=sqrt( factor / n) )
shape에 입력데이터가 들어가고 평균이 0, 표준편차가 sqrt((factor=2) / n(FAN_IN)) 인 절사평균 분포를 return 한다.
2. tf.layers.dense(): >>>> keras.layers.dense 로 바뀜

앞서 구현한 neuron_layer와 비슷하다. bias를 따로 설정하지 않아도 알아서 만들어줌
WX + b (affine transformation) 을 만들어 반환하는 함수.
activation=None 은 기본 값으로 linear activation을 뜻한다. use_bias=True가 기본 값으로 boolean형태이며 참이면 bias를 만들어사용한다. kernel_initializer=None은 가중치를 초기화하는 메서드로 None은 tf.get_variable에서 사용하는 기본 initializer로 초기화한다.
with tf.Session() as sess: 에서 모르는 것:
- np.infty
- open 함수
1. np.infty : 무한대값을 나타냄
|
1 2 |
A = np.infty #무한대값 print(A) |
![]()
2. open(file, mode=’r’, buffering=-1, …) :
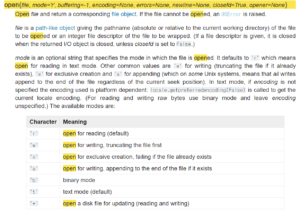
file : 에 적힌 path를 연다.
mode : (r)읽기, (w)쓰기, (x)배타적 생성, (a)끝에 추가해서 쓰기, (b)이진파일
open 함수 예시:
|
1 2 3 4 |
if os.path.isfile("C:\\Users\\고영민\\새파일.txt"): with open("C:\\Users\\고영민\\새파일.txt", "rb") as f: # 이진파일 읽기 start_epoch = int(f.read()) print("새파일을 int형으로 읽어들인것 :", start_epoch) |
![]()
