Mnist 와 XOR 데이터의 비선형성 추측
예전에 Mnist 데이터를 CNN 으로 돌릴 때, CNN 과 DNN 쪽 모두에 활성화 함수를 빼고 max pooling 만 진행한 결과 accuracy 가 90초반대로 높게 나왔던 것을 알 수 있었다. 그래서 문득 혹시 비선형성을 다 제외하면 어떻게 될까라는 의문에 코드를 돌렸다. 추측 결과는 분류에 대한 문제는 마지막 항에 softmax 를 사용하기 때문에 이 부분에서 비선형성을 가지게 되고 XOR 문제는 이 비선형 모듈만으로는 문제를 풀지 못했고 Mnist는 softmax 비선형 모듈만 사용했는데도 90 초반의 정확성을 보였다. 데이터의 비선형성이 case by case 라고 짐작해본다.
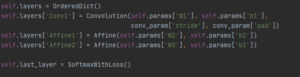
1. CNN ( 합성곱 필터 (10,1,3,3), DNN 히든 노드 200 , 출력 노드 10 softmax , cross-entropy) 모델 (활성화 함수 사용 x)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import numpy as np import matplotlib.pyplot as plt from CNN_code import * from tensorflow.keras import datasets from keras.utils import np_utils (X_train, y_train), (X_test, y_test) = datasets.mnist.load_data() X_train = np.reshape(X_train, (60000,1,28,28)) X_test = np.reshape(X_test, (10000,1,28,28)) y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) X_train = X_train /255. X_test = X_test /255. key_list = ['W1', 'W2', 'b2', 'W3', 'b3'] network = CNNNoacti() for epoch in range(70): for X_batch, y_batch in mini_batch(X_train,y_train, batch_size=200): grads = network.gradient(X_batch,y_batch) for key in key_list: network.params[key] -= 0.01 * grads[key] if epoch % 10 == 0: print(epoch, " th epoch , test acc :", network.accuracy(X_test,y_test)) print(epoch, " th epoch , test loss :", network.loss(X_test,y_test)) |
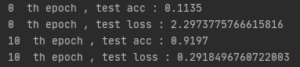
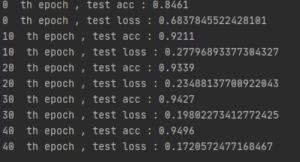
2. DNN (784 200 10 softmax cross-entropy) 모델 , 활성화함수 사용 x

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import numpy as np import matplotlib.pyplot as plt from CNN_code import * from tensorflow.keras import datasets from keras.utils import np_utils (X_train, y_train), (X_test, y_test) = datasets.mnist.load_data() X_train = np.reshape(X_train, (60000,784)) X_test = np.reshape(X_test, (10000,784)) y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) X_train = X_train /255. X_test = X_test /255. key_list = ['W1', 'b1', 'W2', 'b2'] network = MultiLayerNet(input_size=784, hidden_size_list=[200], output_size=10) for epoch in range(50): for X_batch, y_batch in mini_batch(X_train,y_train, batch_size=200): grads = network.gradient(X_batch,y_batch) for key in key_list: network.params[key] -= 0.1 * grads[key] if epoch % 10 == 0: print(epoch, " th epoch , test acc :", network.accuracy(X_test,y_test)) print(epoch, " th epoch , test loss :", network.loss(X_test,y_test)) |
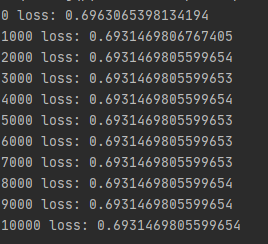
3. XOR 데이터 (입력2 히든레이어1의 노드 2개, 출력 2) 원핫벡터 softmax crossentropy 활성화 함수 x

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# coding: utf-8 import sys, os sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정 import numpy as np import matplotlib.pyplot as plt from Full_code import * from mpl_toolkits.mplot3d import axes3d x_data = np.array([[1,1], [1,0], [0,1], [0,0]], dtype=np.float32) y_data = np.array([[1,0],[0,1], [0,1], [1,0]],dtype=np.float32) #y_data = np.array([[0],[1], [1], [0]],dtype=np.float32) #-------------------------------------------model -------------------------------------------------- network = MultiLayerNet(input_size=2,output_size=2,hidden_size_list=[2]) key_list = [] for i in range(1, 3): key_list.append('W{}'.format(i)) key_list.append('b{}'.format(i)) for i in range(10001): grad = network.gradient(x_data, y_data) # 갱신 for key in key_list: network.params[key] -= 0.1 * grad[key] if i % 1000 == 0: print(i,"loss:",network.loss(x_data,y_data)) |