선형대수학 symmetric matrix 에서 PCA까지
eigenvalue, eigenvector의 개념을 가져와서 대칭행렬에 사용했을 때 실전에서도 많이 쓰는 아주 좋은 성질이 나오며 대칭행렬에서 SVD(특이값분해), PCA(주성분분석) 까지 어떻게 유도되며 어떤 의미를 가지는지 곰곰히 따져가며 공부해봤다.
symmetric matrix 의 diagonalization :

nxn 행렬 A가 직교대각화 가능할 필요충분조건은 A가 대칭행렬인 것이다 라는 정리는 엄청나게 강한 성질이다. 이를 증명하려면 두 가지를 보이면 되는데 첫 째, 직교대각화 가능하면 대칭행렬이다 를 보이는 것이고 (이는 위에서 쉽게 증명했음.) 둘 째, 대칭행렬이면 직교대각화 가능하다는 것을 보이는 것이다. 여기 이 둘째를 증명하는 것이 까다로우며 인터넷에 찾아봐도 쉽게 찾아지지 않는 부분이다. 증명을 따라가보려다가 받아들이는 편이 효율적이어서 그쪽을 선택했다. (훗날 증명해봐야지). 이 정리가 진짜 중요한 이유는 앞서 우리가 봤던 nxn 행렬 A의 eigenvalue,eigenvector 에서는 대각화 가능하려면 (full rank)n개의 일차독립인 고유벡터를 갖는 것이다 라는 것을 배웠는데 대칭행렬에서는 아무런 조건이 필요없이 그냥 대칭행렬 그 자체만으로도 대각화가 가능할 뿐만 아니라 직교하기까지 하다. 향후 이런 성질은 현실문제에서 데이터를 대칭하게 유도하여 뭔가를 많이 해볼 수 있는 기회를 제공한다.(이따 볼 것)
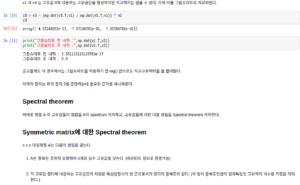
위 마지막질문을 보면 중복된 고유값에 속하는 고유공간의 차원은 대수적 중복도의 수와 같을까? 라는 질문인데 결과적으로 보면 같다. 그렇기 때문에 대칭행렬은 직교대각화 가능하다라는 말이 나올 수 있다. 이 질문에 대한 답은 아래 대칭행렬의 스펙트럼 정리 b 에서 말해준다.
아래 정리에서는 스펙트럼 정리만 보고넘어간다. 왜냐면 그 아래 있는 슈어분해는 대칭행렬이면 직교대각화 가능한 것을 보이기위해 사용한 정리인데 그냥 받아들이기로 했기 때문이다. 마지막에 있는 유니터리 행렬에 대한 정의는 그냥 쉽게 실수체에서 자기자신 행렬과 역행렬이 같은 것이다. (정규직교행렬과 동치)

스펙트럼 분해라는 개념을 소개한다. 스펙트럼 분해는 nxn 대칭행렬에서만 가능한 것이다. 이는 나중에 기약특이값분해전개(reduced SVD expansion) 를 보면 알텐데 기약특이값분해전개는 임의의 mxn행렬에 대해서 비슷한 form으로 전개가 된다. 하지만 정의상으로 이 둘은 다르니 주의해야한다.

위 내용들을 코드로 구현 :


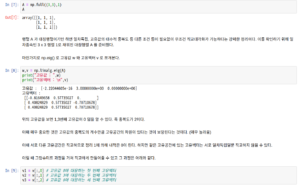

https://github.com/gjtrj55/ML/blob/master/Symmetric_matrix.ipynb
다음은 머신러닝 문제에서 MSE를 다루는 등 가정했을 때 이차형식으로 나오게 되는데 이에 대한 기본 개념을 제시한다. 이 파트의 핵심은 주축정리(principal theorem)이다.


다음은 머신러닝에서 local optimum, global optimum 인지를 확인하는 측도로 쓰일 수 있는 이차형식의 분류 개념을 고유값 개념을 도입해 설명한다.

다음은 제약조건최적화문제(constrained optimization problem)를 이차형식(대칭행렬) 을 가지고 다루는 것을 알아본다. 이는 나중에 바로나올 SVD 을 유도할 때 이해할 수 있는 아이디어를 제시하기 때문에 중요하다.


여기서 중요한 포인트는 두 가지인데 첫 번째는 x벡터의 norm을 1로 잡았다는 것과 x = py 라는 변수변환에서 길이는 변하지 않고 1이 된다는 것이다.(단위벡터이기 때문) , 두 번째는 그렇게 변환된 가장 큰 고유값이 최적화문제에서 최대화값에 해당하고 가장 작은 고유값이 가장 최소화하는 값에 해당한다. 그리고 그에 대응되는 단위 고유벡터들이다.
SVD(특이값분해 : singular value decomposition)
드디어 머신러닝 같은 현실문제에서 굉장히 강력하게 적용되는 특이값분해다. 수치오차적인 관점에서도 고유값분해를 하는 것보다 더 빠르고 정확하다. 장점이 엄청 많은 놈임.
특이값분해는 분해로 나타나는 에서
의 각열을 A의 좌특이벡터(left singular vector),
의 각열을 A의 우특이벡터(right singular vector)라한다. 하지만 여기서 유일한 것은
(특이값) 뿐이며
,
는 유일하지 않음을 알 수 있다.(각각에 마이너스 부호를 붙혀도 곱하면 A가 나온다.) 즉 A를 특이값분해로 나타내는 방법은 유일하지 않다.
앞으로 전개되겠지만 특이값을 유도할 때 위에서 본 제약최적화문제 기법을 사용한다.

singular value decomposition


SVD 가 크게 중요한 의미는 현실적인 문제는 square matrix 처럼 모양이 예쁘지 않다. 대부분 mxn 처럼 직사각행렬이며 이런 직사각행렬을 쪼갤 수 있는 관점을 제시하면서 뭔가를 더욱 들여다볼 수 있는 기회를 주는 것이다.
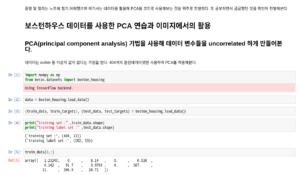
PCA(주성분분석 : principal component analysis) :
이 기법은 활용사례가 엄청 다양하다. 예를들어 영상인식, 통계데이터 분석(주성분찾기), 데이터 압축(차원감소), 노이즈 제거 등 머신러닝에서 중요한 기법으로 역할하고 있다. 이 중 통계데이터 분석과 데이터 압축, 노이즈제거를 알아보겠다.

통계학 관점 (주성분 찾기) :통계학과 선형대수학이 만나는 접점으로 통계학관점에서 접근하면 데이터의 분산, 공분산을 생각해볼 수 있고 이를 선형대수학의 행렬형태로 구현하여 covariance matrix를 이끌어낼 수 있다. 이는 대각방향으로는 자기자신과의 분산, 나머지는 다른 것과의 1:1로 이뤄지는 공분산을 의미하는 행렬이다. 행렬 표기법에 주의(XX’ 와 X’X 데이터 성분에따라 달라짐)
공분산 행렬은 정의상 XX’ 형태인 대칭행렬이다. 대칭행렬은 특이값분해 또는 대각화로 분해할 수 있다. 이때 이 분해가 어떤 의미를 갖는지가 중요하다. 이는 아래에 나와있다.




임을 의미한다. (분산이 보존됨) 이를 프로베니우스 노름 정의, 정리로 증명해본다.

통계학 관점에서 PCA는 성분 변수들과 주성분(벡터)들의 일차결합으로 어떤 새로운 (우리가 설명하기 어려운) 변수를 만들어내며 이 주성분에 projection 시켜 분산이 가장 큰 순서로 나열해 차원을 줄일 수 있다. 대칭행렬인 공분산행렬을 특이값 분해할 수 있으며 분해한 요소는 스펙트럼분해에 의해 전개될 수 있다. (계수가 k일때 )
-> (스펙트럼분해) ->
이때 (
)
의 고유값 크기순이다. 스펙트럼분해를 통해 각 요소는 표준행렬에 projection을 나타낸것이므로 즉, 첫 번째 요소부터 가장 분산이 많이 퍼져있는 정도를 주성분축에 정사영한 것이다. 이 새로운 축은 변수들의 일차결합으로 생성된 것이며 (해석이 어려움, 유일하지 않음) , 시각화 등의 용도에 쓰인다.
코드구현:



데이터 압축(차원 감소):
예를 들어 mxn인 이미지가 있다고 했을 때, 이를 효율적으로 저장하는 방법이 있다. 이런 방법들이 가능한 배경과 이유를 알아본다.


특이값분해에서 좌특이,우특이 벡터가 유일하지 않지만 결과값 A는 같을 수 있다. 계수 r 근사 Ar도 마찬가지로 위의 조건을 충족시에 기약특이값전개에 따라 Ar 값이 유일할 수 있다. 또한 위의 프로베니우스 노름 마지막줄을 보면 증명은 생략되었지만 Ar이 r계수이하인 모든 A 근사들보다 가장 가깝다. 다음은 720 차원을 5차원으로 근사해본 결과다.
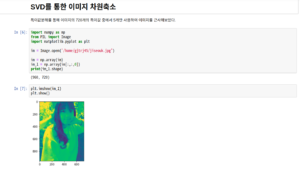
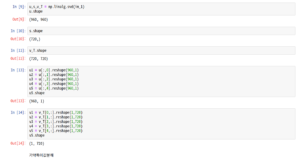
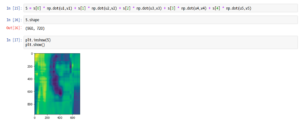
이번엔 sklearn에서 PCA를 사용해봄.



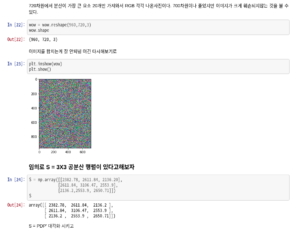

노이즈 제거는 위와 같은 이미지를 특이값분해하면 특이값 순서대로 큰 값 쪽은 사진의 공통적인 특징들을 중간 값 쪽은 특정 사진의 특징들을 작은 값 쪽들은 노이즈로 해석할 수 있다. 그래서 이미지를 머신러닝에서 훈련 시킬 때 SVD 방법을 써서 아주 작은 특이 값은 무시한다. 하지만 이는 연구마다 주관적으로 결정되어진다.