7장: 앙상블 학습, 랜덤포레스트 (p.241)
들어가기 앞서
위키피디아 처럼 전문가의 답보다 수 만명의 사람들이 의견을 모아 내놓은 답이 더 낫다. 이를 대중의 지혜라고 한다. 이와 비슷하게 일련의 예측기로부터 예측을 수집하면 사장 좋은 모델 하나보다 더 좋은 예측을 얻을 수 있을 것이다.
앙상블(Ensemble) : 일련의 예측기
를 학습 시키는 것을 앙상블 학습(Ensemble Learning) 이라고 하며, 앙상블 학습 알고리즘을 앙상블 방법(Ensemble method)라 한다.
결정트리의 앙상블을 랜덤 포레스트(Random Forest)라 한다.
이 장에서는 배깅, 부스팅, 스태킹 등의 앙상블 방법과 랜덤포레스트를 소개한다.
투표 기반 분류기
대수의 법칙 키워드
모든 분류기가 완벽하게 독립적이고 오차에 상관관계가 없다는 가정하에 매우 좋은 성능을 기대할 수 있다.
여러 분류기를 조합하여 사이킷런의 투표 기반 분류기를 만들고 훈련 시킨 코드
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from sklearn.model_selection import train_test_split from sklearn.datasets import make_moons X, y = make_moons(n_samples=500, noise=0.30, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import VotingClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC log_clf = LogisticRegression(solver="liblinear", random_state=42) rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42) svm_clf = SVC(gamma="auto", random_state=42) voting_clf = VotingClassifier( estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)], voting='hard') voting_clf.fit(X_train, y_train) from sklearn.metrics import accuracy_score for clf in (log_clf, rnd_clf, svm_clf, voting_clf): clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(y_test, y_pred)) |
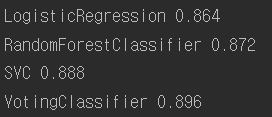
투표 기반 분류기가 다른 분류기보다 성능이 조금 좋은 것을 볼 수 있다.
배깅과 페이스팅
다양한 분류기를 만드는 한 가지 방법은 각기 다른 훈련 알고리즘을 사용하는 것이다. 또 다른 방법으론 같은 알고리즘을 사용하는데 훈련세트의 서브셋을 무작위로 구성하여 분류기를 각기 다르게 학습시키는 것이다.
배깅(bagging) : bootstrap aggregating의 줄임말, 훈련세트에서 중복을 허용하여 샘플링하는 방식 (bootstrapping : 통계학에서 중복을 허용한 resampling 이라한다.)
페이스팅(pasting):중복을 허용치 않고 샘플링하는 방식

사이킷런의 배깅과 페이스팅
단일 결정트리와 500개 트리로 만든 배깅 앙상블 비교

oob 평가
배깅을 사용하면 어떤 샘플은 여러번 선택되고 어떤 것은 한 번도 선택되지 않을 수 있다. 훈련 세트의 크기 만큼인 m개 샘플을 선택하면 이는 평균적으로 63% 정도만 샘플링된다는 것을 의미한다. 나머지 37%를 out-of-bag oob 샘플이라고 부른다.
예측기가 훈련되는 동안에는 oob샘플을 사용하지 않으므로 검증 세트나 교차 검증을 사용하지 않고 oob를 사용해 평가할 수 있다. 앙상블의 평가는 각 예측기의 oob평가를 평균하여 얻는다.
|
1 2 3 4 5 6 7 8 9 |
bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, bootstrap=True, n_jobs=-1, oob_score=True) bag_clf.fit(X_train,y_train) print(bag_clf.oob_score_) y_pred = bag_clf.predict(X_test) print(accuracy_score(y_test,y_pred)) |
![]()
oob_score = True 로 지정하면 훈련이 끝난 후 자동으로 oob평가를 한다. 결과를 보면 89.6%라고 예측한 것에 실제 테스트세트에서 92%니 꽤 비슷하게 예상했다.
Random Forest
https://ko.wikipedia.org/wiki/%EB%9E%9C%EB%8D%A4_%ED%8F%AC%EB%A0%88%EC%8A%A4%ED%8A%B8
일반적으로 배깅방법(또는 페이스팅)을 적용한 결정 트리의 앙상블이다. 랜덤포레스트 알고리즘은 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성을 더 주입한다. 이는 결국 트리를 더욱 다양하게 만들고 편향을 손해보는 대신 분산을 낮추어 전체적으로 더 훌륭한 모델을 만들어낸다.
특성 중요도
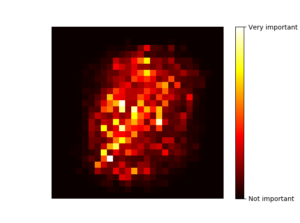
랜덤포레스트의 또 다른 장점은 특성의 상대적 중요도를 측정하기 쉽다는 것이 있다.
다음은 (랜덤포레스트 분류기에서 얻은) MNIST 픽셀 중요도다.
부스팅
약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법을 말한다. 부스팅 방법의 아이디어는 앞의 모델을 보완해 나가면서 일련의 예측기를 학습시키는 것이다. AdaBoost와 Gradient Boosting 대표적인 두 가지 방법에 대해 알아본다.
AdaBoost(Adaptive Boosting)
직관적인 개념으로 이전 예측기를 보완하는 새로운 예측기를 만드는 방법은 이전 모델이 과소적합했던 샘플의 가중치를 더 높혀서 학습하는 것을 반복하는 것이다.

연속된 예측기의 결정 경계
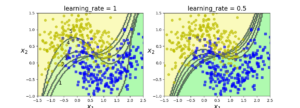
이런 기법에는 중요한 단점이 있는데 각 예측기는 이전 예측기가 훈련되고 평가된 후에 학습될 수 있기에 병렬화(분할)을 할 수 없다. 결국 확장성이 떨어진다.
AdaBoost 이론


Gradient Boosting
부스팅을 기울기 하강법을 이용하여 구현한 방법이다. 기울기 하강 유추기법에서, 각 훈련값(training point)에 대한 분류기의 결과는 n차 공간에서의 점으로 간주되고, 각각의 축은 훈련샘플에, 각 약한 학습기 는 어떤 벡터의 고정된 방향과 길이에 대응되며, 최종 목적은 최소 반복을 통해 목표점(혹은 손실함수값)이 근처 다른 점에서보다 작은 지점)에 도달하는 것이다. 따라서 AdaBoost 알고리즘은 훈련오차의 최적화를 위해 코시 기법(Cauchy, 실험오차를 최소화하는 를 통한 를 찾는 급경사(steepest gradient) 기법) 혹은 뉴턴 기법(Newton, 어떠한 목표점에 가장 가까운 를 가지는를 찾는 기법)을 수행하는 셈이다.







(위키피디아)
Stacking
마지막으로 알아볼 스태킹이란 방법은 ‘앙상블에 속한 모든 예측기의 예측을 취합하는 간단한 함수(직접 투표 같은)를 사용하는 대신 취합하는 모델을 훈련시킬 수 없을까?’ 라는 기본 아이디어로 출발한다.
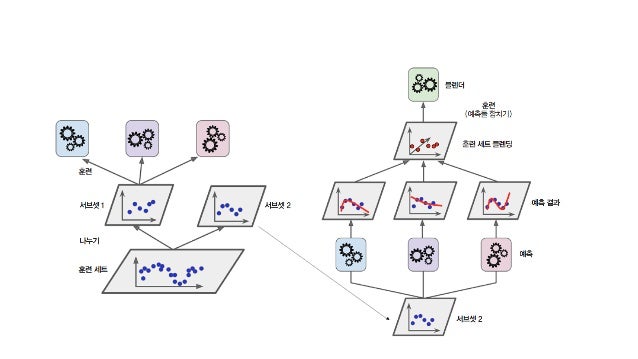
예시 설명 : 훈련세트를 두개의 서브셋으로 나누고 첫 번째 서브셋을 3개의 예측기를 사용해 훈련 시킨다. 그리고 서브셋 2를 예측하는 예측기로 이 세개의 예측기를 사용한다. 예측한 값을 입력 특성으로 사용하는 새로운 훈련 세트를 만들어 훈련한다.
References: Hands – On Machine Learning with Scikit Learn & TensorFlow