3장 : 에러분석 (p.144)
가정 : 이 절에서는 가능성이 높은 모델을 찾았다고 가정하고 이 모델의 성능을 향상시킬 방법을 찾아보는 것이다.
에러분석
모델의 성능을 향상시키는 한 가지 방법으로 만들어진 에러의 종류를 분석하는 것이 있다. 먼저 오차행렬을 살펴볼 수 있다.
|
1 2 3 4 5 6 7 |
#에러분석 y_train_pred = cross_val_predict(sgd_clf,X_train_scaled, y_train, cv=3) conf_mx = confusion_matrix(y_train,y_train_pred) print(conf_mx) plt.matshow(conf_mx, cmap=plt.cm.gray) plt.show() |
X_train_scaled 는 앞 글에서 standard scaler로 조정한 값이다. cross_val_predict함수를 이용해 예측을 만들고 confusion matrix로 정답 레이블인 y_train과 비교한다.
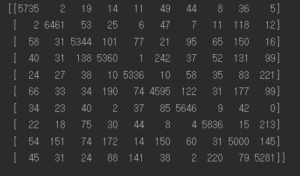
대각방향이 TP, TN 영역 (정확히 맞춘 영역) 이다. 그림으로 표현하면
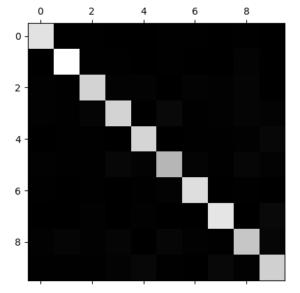
이 그림은 큰 값일수록 흰색, 작은 값일 수록 어두운색을 띄게하는 그래프다. 이 confusion matrix는 비교적 이미지가 올바르게 분류되어있는 것을 알 수 있다. 그리고 숫자 5 (대각방향 6번째) 를 보면 다른 숫자들과 비교해 어두운 것을 볼 수 있는데 해석해보자면 dataset에 숫자5가 별로 없거나, 5를 잘 구분하지 못했을 가능성이 있다는 것이다.
다음은 에러 부분에 초점을 맞춰 작업한거다.
|
1 2 3 4 5 6 7 |
#error 비율 보기 row_sums = conf_mx.sum(axis=1, keepdims=True) # axis=1은 각행을 더한것,차원은유지 norm_conf_mx = conf_mx / row_sums np.fill_diagonal(norm_conf_mx, 0) plt.matshow(norm_conf_mx, cmap=plt.cm.gray) plt.show() |
오차행렬의 각 행은 하나의 클래스(ex:답이5인클래스)를 나타내기 때문에 행의 각 값에 클래스 이미지 개수(해당 행의 합)로 나누어 에러 비율을 비교한다. 그리고 에러를 비교해 보는 것이므로 TP,TN구역은 0으로 채워 넣어 시각화를 돕는다.
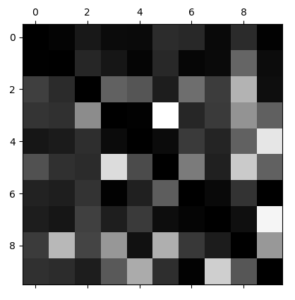
행은 실제 클래스를 열은 예측 클래스를 나타내는데 클래스 8,9열이 다른 열들보다 밝은 것을 볼 수 있다(에러비율이 비교적 크다). 숫자 0과 1의 행과 열을 보면 비교적 에러 비율이 적은 것을 볼 수 있다. 참고할 점은 에러가 대칭이 아니다. 또한 3과 5를 보면 대칭적으로 흰 부분을 볼 수 있는데 이는 서로 혼돈되는 것이다.
이제 8과 9를 잘 분류하게 하고 3과 5가 서로 헷갈리게 구분하지 않도록 문제점을 파악했다. 해결책은 여러 방법이 있을 수 있는데, 훈련 데이터를 더 모으는 방법이 있을 수 있고 분류기에 도움이 될 만한 특성을 더 찾아 볼 수도 있다(ex: 동심원의 수를 세는 알고리즘 등)
여기서 전체적인 관점말고 개개의 에러를 분석해보면 정확한 에러를 파악할 수 있지만 문제는 언제 하나하나 다하고 있는가이다. 예제에서는 3과 5의 샘플을 그려본다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#개개의 에러 cl_a, cl_b = 3,5 X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)] X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)] X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)] X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)] def plot_digit(data): image = data.reshape(28, 28) plt.imshow(image, cmap = mpl.cm.binary, interpolation="nearest") plt.axis("off") def plot_digits(instances, images_per_row=10, **options): size = 28 images_per_row = min(len(instances), images_per_row) images = [instance.reshape(size,size) for instance in instances] n_rows = (len(instances) - 1) // images_per_row + 1 row_images = [] n_empty = n_rows * images_per_row - len(instances) images.append(np.zeros((size, size * n_empty))) for row in range(n_rows): rimages = images[row * images_per_row : (row + 1) * images_per_row] row_images.append(np.concatenate(rimages, axis=1)) image = np.concatenate(row_images, axis=0) plt.imshow(image, cmap = mpl.cm.binary, **options) plt.axis("off") plt.figure(figsize=(8,8)) plt.subplot(221); plot_digits(X_aa[:25], images_per_row=5) plt.subplot(222); plot_digits(X_ab[:25], images_per_row=5) plt.subplot(223); plot_digits(X_ba[:25], images_per_row=5) plt.subplot(224); plot_digits(X_bb[:25], images_per_row=5) plt.show() |

원인은 linear model인 SGDClassifier를 사용했기 때문이다. 선형 분류기는 클래스마다 픽셀에 가중치를 할당하고 새로운 이미지에 대해 단순히 픽셀 강도의 가중치 합을 클래스의 점수로 계산한다. 따라서 3과 5는 몇 개의 픽셀만 다르기 때문에 모델이 쉽게 혼동한다.
3과 5의 주요차이는 위쪽 선과 아래쪽 호를 이어주는 작은 직선의 위치다. 숫자 3을 쓸 때 연결 부위가 조금 왼쪽으로 치우치면 분류기가 5로 분류하고 또 반대도 마찬가지다. 분류기는 이미지의 위치나 회전 방향에 매우 민감하다. 에러를 줄이는 한 가지 방법은 이미지를 중앙에 위치시키고 회전되어 있지 않도록 전처리 하는 것이다.
References : Hands – On Machine Learning with Scikit Learn & TensorFlow