3장 : 다중분류 (p.141)
다중분류 ( Multiclass classification ) 개요
다중 분류기(multiclass classifier) 는 둘이상의 클래스를 구별하는 방법이다.
- 여러개의 클래스를 직접 처리할 수 있는 알고리즘 ( 랜덤포레스트, 나이브베이즈등)
- 이진 분류만 가능한 알고리즘( SVM, 선형분류기 등)
이 있는데 이진 분류기를 여러개 사용하여 다중 클래스를 분류하는 기법도 많다. 이에 대해 알아보자
일대다 전략(OvA) one – versus – all
예를 들어 특정 숫자 하나만 구분하는 숫자별 이진분류기 10개( 0~9 )를 훈련시켜 클래스가 10개인 숫자 이미지 분류 시스템을 만들 수 있다. 이미지를 분류할 때 각 분류기의 결정 점수 중에서 가장 높은 것을 클래스로 선택한다.
일대일 전략(OvO) one – versus – one
0과 1 구별, 0과 2 구별, 1과 2 구별 등과 같이 각 숫자의 조합마다 이진분류기를 훈련 시키는 것이다. 클래스가 N개라면 분류기는 이항 계수의 성질과 조합(combination)으로 N x (N-1) / 2 개만큼 필요하다. MNIST 처럼 10개의 클래스를 다루려면 45개가 필요한데 그 중 가장 많이 양성으로 분류된 클래스를 선택한다. 일대일 전략의 장점은 0과 1 샘플을 훈련시킬 때 이 둘만 필요하지 다른 것들은 필요 없다는 것이다. 즉 각 분류기의 훈련의 전체 훈련 세트 중 구별할 두 클래스에 해당하는 샘플만 필요하다.
선호도 :
SVM 같은 일부 알고리즘은 훈련세트 크기에 민감해서 큰 훈련세트에서 몇 개의 분류기를 훈련시키는 것보다 작은 훈련세트에서 많은 분류기를 훈련시키는 쪽이 빠르므로 OvO를 선호한다(진짜 그러한가?). 하지만 대부분의 이진 분류 알고리즘에서는 OvA를 선호한다. (왜 그렇지?)
다중 클래스 분류 MNIST를 이진 분류 알고리즘으로 다루기
|
1 2 3 4 |
#다중 분류 sgd_clf.fit(X_train,y_train) print(sgd_clf.predict([some_digit])) # some_digit = 36000 print(y[36000]) |
다중 클래스 분류 작업에 이진 분류 알고리즘을 선택하면 sklearn이 자동으로 감지해 OvA(SVM 일때는 OvO)를 적용한다. sgd분류기로 학습 후 특정숫자를 예측한 결과 ![]() (잘예측했다.)
(잘예측했다.)
|
1 2 |
some_digit_scores = sgd_clf.decision_function([some_digit]) print(some_digit_scores) |
내부에서는 sklearn이 실제로 10개의 이진분류기를 훈련시키고 각각의 결정 점수를 얻어 가장 높은 클래스를 선택한다.
sgd_clf 는 일대다 전략을 사용하므로 decision_function()메서드를 사용해 [some_digit] 값을 출력해보면 각각의 클래스마다 하나씩, 총 10개의 점수를 반환한다. 그중 151,219점의 점수로 5를 가리키는 점수 값이 가장 높다.
|
1 2 3 |
print("some_digit점수중 가장 큰값 :",np.argmax(some_digit_scores)) print("class 종류 : ",sgd_clf.classes_) print("[5]인덱스 class :",sgd_clf.classes_[5]) |
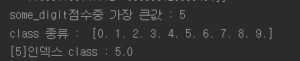
참고 : 분류기가 훈련될 때 classes_ 속성에 타깃 클래스의 리스트를 값으로 정렬하여 저장한다.
OvO나 OvA를 선택해서 사용하고 싶은 경우
sklearn에서 OvO나 OvA를 선택해서 사용하려면 OneVsOneClassifier 또는 OneVsRestClassifier를 사용한다. 간단히 대입만 하면된다.
|
1 2 3 4 5 |
#OvO OR OvA 선택해서 사용하기 ovo_clf = OneVsOneClassifier(SGDClassifier(max_iter=5, random_state=42)) ovo_clf.fit(X_train,y_train) print("일대일을 사용한 sgd분류기의 예측 값:",ovo_clf.predict([some_digit])) print("일대일 추정값 개수 :",len(ovo_clf.estimators_)) |
![]()
RandomForestClassifier를 훈련시키는 것도 간단하다.
|
1 2 3 |
forest_clf = RandomForestClassifier(random_state=42) forest_clf.fit(X_train, y_train) print(forest_clf.predict([some_digit])) |
![]() 위에 앞서 말했듯이 랜덤포레스트분류기는 여러개의 클래스를 직접처리 할 수 있는 알고리즘이어서 OvA,OvO가 필요 없다. predict_proba() (확률) 메서드를 호출하면 분류기가 각샘플에 부여한 클래스별 확률을 얻을 수 있다.
위에 앞서 말했듯이 랜덤포레스트분류기는 여러개의 클래스를 직접처리 할 수 있는 알고리즘이어서 OvA,OvO가 필요 없다. predict_proba() (확률) 메서드를 호출하면 분류기가 각샘플에 부여한 클래스별 확률을 얻을 수 있다.
|
1 |
print(forest_clf.predict_proba([some_digit])) |
![]()
너무 깔끔하게 5클래스를 100%가리키고 있다.
분류기평가
일반적으로 분류기의 평가에는 교차 검증을 사용한다. SGDClassifier의 정확도를 평가해 보자.
|
1 2 |
#분류기 평가 print(cross_val_score(sgd_clf,X_train,y_train, cv=3, scoring="accuracy")) |
정확도로 SGD분류기를 평가한 결과 :![]()
모든 테스트 fold에서 85%이상이 나왔다. 하지만 입력 스케일을 조정함(2장에서처럼)으로써 정확도를 90%이상 높일 수 있다.
|
1 2 3 |
scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) print(cross_val_score(sgd_clf, X_train_scaled,y_train, cv=3,scoring="accuracy")) |
![]()
*데이터 전처리 함수에 관해 (standard scaler도)
https://datascienceschool.net/view-notebook/f43be7d6515b48c0beb909826993c856/
전체코드 :
앞전 코드에 이어서
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#다중 분류 sgd_clf.fit(X_train,y_train) #print(sgd_clf.predict([some_digit])) # some_digit = 36000 some_digit_scores = sgd_clf.decision_function([some_digit]) #print(some_digit_scores) #print("some_digit점수중 가장 큰값 :",np.argmax(some_digit_scores)) #print("class 종류 : ",sgd_clf.classes_) #print("[5]인덱스 class :",sgd_clf.classes_[5]) #OvO OR OvA 선택해서 사용하기 #ovo_clf = OneVsOneClassifier(SGDClassifier(max_iter=5, random_state=42)) #ovo_clf.fit(X_train,y_train) #print("일대일을 사용한 sgd분류기의 예측 값:",ovo_clf.predict([some_digit])) #print("일대일 추정값 개수 :",len(ovo_clf.estimators_)) #forest_clf = RandomForestClassifier(random_state=42) #forest_clf.fit(X_train, y_train) #print(forest_clf.predict([some_digit])) #print(forest_clf.predict_proba([some_digit])) #분류기 평가 #print(cross_val_score(sgd_clf,X_train,y_train, cv=3, scoring="accuracy")) #scaler = StandardScaler() #X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) #print(cross_val_score(sgd_clf, X_train_scaled,y_train, cv=3,scoring="accuracy")) |
References : Hands – On Machine Learning wiht Scikit – Learn & Tensorflow