3장 : 분류 (p.123)
supervised learning 에서 discrete한 성질을 다룰 때 쓰는 방법이다.
MNIST dataset 을 이용한다.
MNIST
sklearn 에서 읽어들인 dataset들은 일반적으로 비슷한 dictionary 구조를 가지고 있다.
|
1 2 3 |
from sklearn.datasets import fetch_mldata mnist = fetch_mldata('MNIST original') print(mnist) |

- dataset을 설명하는 DESCR 키
- sample이 하나의 행, 특성이 하나의 열로 구성된 배열을 가진 data 키
- label 배열을 담고 있는 target 키
|
1 2 3 |
X, y = mnist["data"], mnist["target"] print(X.shape) print(y.shape) |
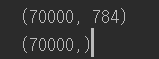
이미지가 70,000개가 있고 각 이미지는 784개의 특성을 가지고 있다. (28 X 28 fixel) 이를 그림 형태로 표현해보면
|
1 2 3 4 5 6 7 8 |
some_digit = X[36000] some_digit_image = some_digit.reshape(28,28) plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, interpolation="nearest") plt.axis("off") plt.show() print(y[36000]) |

![]()
X[36000] 의 그림은 5처럼 보이고 그의 답인 y[36000]이 5라고 하고 있다.
주의 : data를 자세히 조사하기 전에는 항상 test set를 만들고 따로 떼어 놓아야 한다.
|
1 2 3 4 |
#데이터 분류 X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] shuffle_index = np.random.permutation(60000) X_train, y_train = X_train[shuffle_index], y_train[shuffle_index] |
데이터셋을 섞어서 랜덤한 결과를 만들수 있게 해준다.
이진분류기 훈련
|
1 2 3 4 5 6 7 8 9 10 |
#이진 분류기 훈련 #target vector making y_train_5 = (y_train == 5) # 5는 True 나머지는 False y_test_5 = (y_test == 5) #분류 모델 :SGD 사용 sgd_clf = SGDClassifier(max_iter=5, random_state=42) sgd_clf.fit(X_train, y_train_5) print(sgd_clf.predict([some_digit])) |
숫자 5를 식별해주는 모델을 만들어 보려한다. 5인가 아닌가만 분류하기 때문에 binary classifier 의 한 예시다. 분류 모델로는 SGD(확률적 경사 하강법) 분류기를 사용했는데 이 classifier는 매우 큰 dataset을 효율적으로 처리하는 장점을 지니고 있다. 숫자 5에 대한 예측을 해본 결과
![]() 아직 맞추지는 못하는 거 같다.
아직 맞추지는 못하는 거 같다.
성능측정
들어가기 앞서 KFold 교차 검증에 대해 알아보자.
교차 검증을 사용한 정확도 측정
가끔 sklearn이 제공하는 기능보다 교차 검증 과정을 더 많이 제어해야할 필요가 있다. 이때는 직접 기능을 구현하면 된다. 예시코드 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#교차 검증 구현 skfolds = StratifiedKFold(n_splits= 3, random_state=42) for train_index, test_index in skfolds.split(X_train,y_train_5): clone_clf = clone(sgd_clf) ##복사본 만들기 X_train_folds = X_train[train_index] y_train_folds = y_train_5[train_index] X_test_fold = X_train[test_index] y_test_fold = y_train_5[test_index] clone_clf.fit(X_train_folds, y_train_folds) y_pred = clone_clf.predict(X_test_fold) n_correct = sum(y_pred == y_test_fold) print("교차검증 구현: ",n_correct / len(y_pred)) print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")) |
StratifiedKFold는 클래스별 비율이 유지되도록 fold를 만들기 위해 계층적 샘플링을 수행합니다. 매 반복에서 분류기 객체를 복제하여 훈련 fold를 훈련시키고 테스트 fold로 예측을 만든다. 그런 다음 올바른 예측의 수를 세어 정확한 예측의 비율을 출력한다.
마지막코드는 cross_val_score() 함수로 fold가 3개인 K-겹 교차 검증을 사용해 SGDClassifier model을 평가한 것이다.
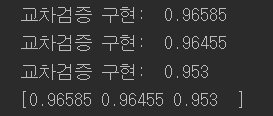
모든 교차 검증 폴드에 대해 accuracy가 95%이상이다. 모든 이미지를 5 아님 클래스로 분류하는 더미 분류기를 만들어 비교해본다. 뭐가 주어지든지 5가 아니라고 하는 분류기다. 5는 1-9 image dataset에서 약 10%정도만 차지하기 때문에 결과는 아래와 같다.
|
1 2 3 4 5 6 7 8 9 |
#5아님 더미클래스 분류 후비교 class Never5Classifier(BaseEstimator): def fit(self,X, y=None): pass def predict(self,X): return np.zeros((len(X),1), dtype=bool) never_5_clf = Never5Classifier() print(cross_val_score(never_5_clf,X_train,y_train_5, cv=3, scoring="accuracy")) |
![]()
정확도가 90%이다. 정확도가 95%와 90%인데 이는 정확도를 분류기의 성능 측정 지표로 선호하지 않는 이유를 보여준다. 특히 불균형한 데이터셋을 다룰 때( 어떤 클래스가 다른 것보다 월등히 많은 경우) 더욱 그렇다.
오차 행렬 confusion matrix
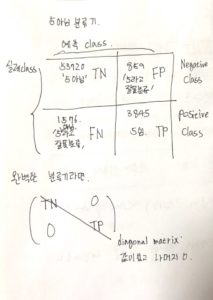
위에서 측정지표로 정확도(전체 데이터에서 몇개나 맞추었는가?)를 사용하였는데 이는 앞서 보았듯이 좋은 측정지표의 역할을 하지 못하는 것을 볼 수 있다. 다른 방법으로 오차행렬이라는 것이 있는데, 기본적인 idea는 클래스 A의 샘플이 클래스 B로 분류된 횟수를 세는 것이다(즉 오차, 틀린 것만큼 counting 한다.)
confusion matrix 에 대해

|
1 2 3 |
#오차 행렬 y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5,y_train_pred)) |
cross_val_score() 함수처럼 cross_val_predict() 함수는 K-겹 교차 검증을 수행하지만 평가 점수를 반환하지 않고 각 테스트 fold에서 얻은 예측을 반환한다. (위 예시에서 cv=3 이니까 K-fold 3겹이고 3개의 예측 행렬이 생기는데 이를 평균해서 나온 값인가?)
cross_val_score() 는 비율을 반환하지만 cross_val_predict() 함수는 예측을 반환한다. (data 자체를) . 이제 이 data로 오차를 볼 수 있다.

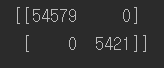
|
1 2 |
#완벽한 오차가 없는 행렬일 경우 print(confusion_matrix(y_train_5,y_train_5)) |
정밀도와 재현율
많이 쓰이는 것 중 양성 예측의 정확도가 있다. 이를 분류기의 정밀도(precision)라고 한다.
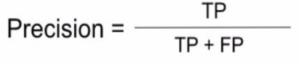 (TP = 진짜 양성의 수 , FP = 거짓양성의 수)
(TP = 진짜 양성의 수 , FP = 거짓양성의 수)
Precision은 재현율(recall)이라는 또 다른 지표와 같이 사용하는 것이 일반적이다. 재현율은 분류기가 정확하게 감지한 양성 샘플의 비율로 ![]()
민감도(sensitivity or true positive rate TPR) 이라고도 한다.
|
1 2 3 |
#정밀도와 재현율 print("정밀도 :",precision_score(y_train_5, y_train_pred)) #정밀도 print("재현율 :",recall_score(y_train_5,y_train_pred)) #재현율 |

정밀도 : TP / (TP +FP) = 4,218 / (4,218 + 1,356) = 0.756..
재현율 : TP / P = 4,218 / (1,203 + 4,218) = 0.778..
(여러번 돌려봤는데 계산 값 차이가 좀 크게 상이하다)
정밀도와 재현율을 F1 score 라고 하는 하나의 숫자로 만들면 두 분류기를 비교할 때 편하다. F1 score는 정밀도와 재현율의 조화 평균 (harmonic mean) 이다.

|
1 2 |
#F1 score (조화평균) print("조화 평균 :", f1_score(y_train_5,y_train_pred)) |
![]()
여기서 평균에 대한 정리를 하고 가면 좋겠다.

내용을 정리해보면
정확도 ( 올바르게 추측한 data / 전체 data ) 로만 성능을 측정하는 지표로만 삼기에는 문제가 생긴다. 예를 들어 5가 1개만 있는 100개의 숫자 dataset에서 ‘전부 5가 아니다’라고 추측하는 분류기의 정확도는 99/100 (99%) 다. 하지만 confusion matrix에서 precision TP / (TP + FP) 으로 보면 0 / 100 즉, 0%다. 이처럼 성능을 어떤 지표를 이용해야 합리적으로 표현할 수 있는가에 대한 해답으로 confusion matrix가 제시된다.
예를 들어 생명이 좌지우지되는 상황을 구분하는 문제를 생각해보자. 뱀을 보고 도망갈지 가만히 있을지 결정하는 머신러닝이면
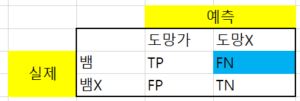
confusion matrix에서 실제로 FN의 영향이 매우 클 것이다. 왜냐하면 뱀인데 도망가지 않으면 죽은 거니까 매우 심각한 상황이 발생한다. 이때는 성능을 측정하는 지표로 FN에 많은 가중치를 부과해 중요성을 올리는 것이다. F-Measure로 표현해보자면 FN는 재현율(Recall)에 해당하니 식을
 이렇게 써볼 수 있겠다.
이렇게 써볼 수 있겠다.
문제를 어떻게 정의하느냐에 따라 어떤 것을 가중하게 둘 것인지를 잘 이해해야한다.
confusion matrix 에 대해 명확한 개념설명이 된 사이트
https://sumniya.tistory.com/26
precision recall trade – off
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#결정 임계값에 대한 정밀도와 재현율 y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(thresholds, precisions[:-1], "b--", label="precision") plt.plot(thresholds, recalls[:-1], "g-", label = "recall") plt.xlabel("threshold") plt.legend(loc="center left") plt.ylim([0,1]) plot_precision_recall_vs_threshold(precisions,recalls,thresholds) plt.show() |
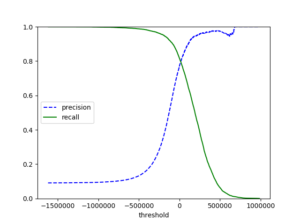
정밀도와 재현율의 관계는 trade – off 하다 설명할 수 있다.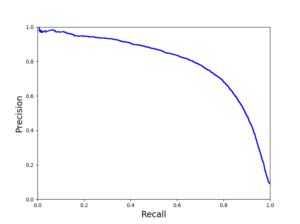
작업에 맞는 최선의 정밀도/재현율 trade-off 를 만드는 임계값을 선택하면 된다. 정밀도 90%를 달성하는 것이 목표라면 위 두 그래프를 보고 code를 구현한다.
|
1 2 3 |
y_train_pred_90 = (y_scores > 70000) print(precision_score(y_train_5,y_train_pred_90)) print(recall_score(y_train_5,y_train_pred_90)) |
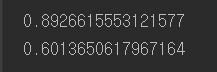 90%에 거의 가깝다.
90%에 거의 가깝다.
ROC 곡선
수신기 조작 특성 (receiver operating characteristic)
거짓 양성비율 (FPR)에 대한 진짜 양성 비율(TPR)의 곡선이다.

위의 정리로 부터 ROC 곡선은 민감도(재현율) 에 대한 1- 특이도(specificity) 그래프다. 그래프를 그려보면
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#ROC곡선 fpr, tpr, thresholds = roc_curve(y_train_5,y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0,1],[0,1],'k--') plt.axis([0,1,0,1]) plt.xlabel("False positive rate") plt.ylabel("True positive rate") plot_roc_curve(fpr,tpr) plt.show() |
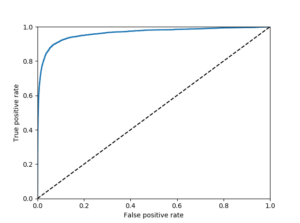
여기에도 trade-off 관계가 있다. 왜 있는지 이해 필요. 재현율(TPR)이 높을 수록 분류기가 만드는 거짓 양성(FPR)이 늘어난다. 점선은 완저난 랜덤 분류기의 ROC곡선을 뜻한다. 좋은 분류기는 이 점선과 멀리 떨어져있어야 한다.(왼쪽 위 모서리)
곡선아래의 면적(area under the curve) AUC를 측정하면 분류기들을 비교할 수 있다. 완벽한 분류기는 1이고, 완전한 랜덤분류기는 0.5다.
|
1 |
print(roc_auc_score(y_train_5,y_scores)) |
![]()
Tip: 각 방법들에 대해서 언제 사용해야 적절한지 ?
- PR(정밀도재현율)곡선: 일반적인 법칙은 양성클래스가 드물거나 거짓음성(FN)보다 거짓양성(FP)가 더 중요할 때 사용한다.
- ROC곡선 : PR곡선의 사용조건을 제외한 조건에서 사용한다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#2개의 분류기를 ROC로 비교 forest_clf = RandomForestClassifier(random_state=42) #랜덤포레스트는 decision_fun메서드가 없어 predict_proba 를사용 y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,method="predict_proba") y_scores_forest = y_probas_forest[:,1] #양성클래스에 대한 확률을 점수로 사용 fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest) plt.plot(fpr,tpr,"b:", label="SGD") plot_roc_curve(fpr_forest,tpr_forest,"random_forest") plt.legend(loc="lower right") plt.show() |
|
1 |
print(roc_auc_score(y_train_5,y_scores_forest)) |
RandomForestClassifier와 SGDClassifier 를 ROC 곡선에서 AUC로 비교해보는 코드이다.
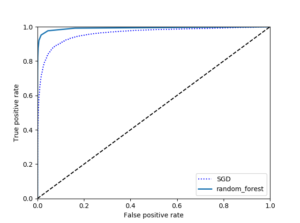
![]() Random forest 가 AUC점수가 훨씬 높은 것을 볼 수 있다.
Random forest 가 AUC점수가 훨씬 높은 것을 볼 수 있다.
전체 코드 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 |
from sklearn.datasets import fetch_mldata from sklearn.linear_model import SGDClassifier from sklearn.model_selection import cross_val_score from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_recall_curve from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import roc_auc_score from sklearn.metrics import roc_curve from sklearn.metrics import f1_score from sklearn.metrics import precision_score, recall_score from sklearn.metrics import confusion_matrix from sklearn.base import BaseEstimator from sklearn.base import clone import matplotlib import matplotlib.pyplot as plt import numpy as np mnist = fetch_mldata('MNIST original') #print(mnist) X, y = mnist["data"], mnist["target"] #print(X.shape) #print(y.shape) #그림 확인해보기 some_digit = X[36000] #some_digit_image = some_digit.reshape(28,28) #plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, # interpolation="nearest") #plt.axis("off") #plt.show() #print(y[36000]) #데이터 분류 X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] shuffle_index = np.random.permutation(60000) X_train, y_train = X_train[shuffle_index], y_train[shuffle_index] #이진 분류기 훈련 #target vector making y_train_5 = (y_train == 5) # 5는 True 나머지는 False y_test_5 = (y_test == 5) #분류 모델 :SGD 사용 sgd_clf = SGDClassifier(max_iter=5, random_state=42) sgd_clf.fit(X_train, y_train_5) #print(sgd_clf.predict([some_digit])) #교차 검증 구현 skfolds = StratifiedKFold(n_splits= 3, random_state=42) for train_index, test_index in skfolds.split(X_train,y_train_5): clone_clf = clone(sgd_clf) X_train_folds = X_train[train_index] y_train_folds = y_train_5[train_index] X_test_fold = X_train[test_index] y_test_fold = y_train_5[test_index] clone_clf.fit(X_train_folds, y_train_folds) y_pred = clone_clf.predict(X_test_fold) n_correct = sum(y_pred == y_test_fold) # print("교차검증 구현: ",n_correct / len(y_pred)) #print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")) #5아님 더미클래스 분류 후비교 class Never5Classifier(BaseEstimator): def fit(self,X, y=None): pass def predict(self,X): return np.zeros((len(X),1), dtype=bool) never_5_clf = Never5Classifier() #print(cross_val_score(never_5_clf,X_train,y_train_5, cv=3, scoring="accuracy")) #오차 행렬 y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) #print("오차행렬") #print(confusion_matrix(y_train_5,y_train_pred)) #완벽한 오차가 없는 행렬일 경우 #print(confusion_matrix(y_train_5,y_train_5)) #정밀도와 재현율 #print("정밀도 :",precision_score(y_train_5, y_train_pred)) #정밀도 #print("재현율 :",recall_score(y_train_5,y_train_pred)) #재현율 #F1 score (조화평균) #print("조화 평균 :", f1_score(y_train_5,y_train_pred)) #정밀도 재현율 trade - off #y_scores = sgd_clf.decision_function([some_digit]) #print(y_scores) #threshold = 0 #y_some_digit_pred = (y_scores > threshold) #print(y_some_digit_pred) #threshold = 200000 #y_some_digit_pred = (y_scores > threshold) #print(y_some_digit_pred) #결정 임계값에 대한 정밀도와 재현율 y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(thresholds, precisions[:-1], "b--", label="precision") plt.plot(thresholds, recalls[:-1], "g-", label = "recall") plt.xlabel("threshold") plt.legend(loc="center left") plt.ylim([0,1]) #plot_precision_recall_vs_threshold(precisions,recalls,thresholds) def plot_precision_vs_recall(precisions, recalls): plt.plot(recalls, precisions, "b-", linewidth=2) plt.xlabel("Recall", fontsize=16) plt.ylabel("Precision", fontsize=16) plt.axis([0, 1, 0, 1]) #plt.figure(figsize=(8, 6)) #plot_precision_vs_recall(precisions, recalls) #plt.show() #y_train_pred_90 = (y_scores > 70000) #print(precision_score(y_train_5,y_train_pred_90)) #print(recall_score(y_train_5,y_train_pred_90)) #ROC곡선 fpr, tpr, thresholds = roc_curve(y_train_5,y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0,1],[0,1],'k--') plt.axis([0,1,0,1]) plt.xlabel("False positive rate") plt.ylabel("True positive rate") #plot_roc_curve(fpr,tpr) #plt.show() #print(roc_auc_score(y_train_5,y_scores)) #2개의 분류기를 ROC로 비교 forest_clf = RandomForestClassifier(random_state=42) #랜덤포레스트는 decision_fun메서드가 없어 predict_proba 를사용 y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,method="predict_proba") y_scores_forest = y_probas_forest[:,1] #양성클래스에 대한 확률을 점수로 사용 fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest) plt.plot(fpr,tpr,"b:", label="SGD") plot_roc_curve(fpr_forest,tpr_forest,"random_forest") plt.legend(loc="lower right") plt.show() print(roc_auc_score(y_train_5,y_scores_forest)) |
References: Hands – On Machine Learning with Scikit Learn & Tensorflow