2장: 머신러닝프로젝트 처음부터 끝까지 (p.110)
모델 선택과 훈련
모델은 linear regression을 선택했고 5개의 데이터를 학습해서 정답 레이블과 비교해봤다.
|
1 2 3 4 5 6 7 8 9 |
#모델 선택과 훈련 lin_reg = LinearRegression() lin_reg.fit(housing_prepared, housing_labels) some_data = housing.iloc[:5] some_labels = housing_labels.iloc[:5] some_data_prepared = full_pipeline.transform(some_data) print("예측 :",np.round(lin_reg.predict(some_data_prepared))) print("레이블 :",list(some_labels)) |
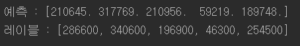
아주 정확한 예측은 아니지만 작동은한다. 사이킷런의 mean_square_error 함수를 사용해 전체 훈련 세트에 대한 regression model의 RMSE를 측정해본다.
|
1 2 3 4 |
housing_predictions = lin_reg.predict(housing_prepared) lin_mse = mean_squared_error(housing_labels,housing_predictions) lin_rmse = np.sqrt(lin_mse) print(lin_rmse) |
![]()
좋은 점수는 아니다. 대부분 구역의 중간 주택 가격은 120,000~265,000 사이인데 예측 오차가 70,000가까이 되는 것은 모델이 훈련 데이터에 과소적합된 사례이다. 모델의 규제를 감소시키거나 더 강력한 모델을 세우는 것이다. 여기서는 다른 모델을 사용하는 것을 해본다.
|
1 2 3 4 5 6 7 8 |
#강력한 모델찾기 tree_reg = DecisionTreeRegressor() tree_reg.fit(housing_prepared, housing_labels) housing_predictions = tree_reg.predict(housing_prepared) tree_mse = mean_squared_error(housing_labels,housing_predictions) tree_rmse = np.sqrt(tree_mse) print(tree_rmse) |
![]()
overfitting 사례이다. 확신이 드는 모델이 론칭할 준비가 되 전까지 테스트 세트는 사용하지 않으려 하므로 훈련세트의 일부분으로 훈련을 하고 다른 일부분은 모델 검증에 사용해야 한다.

교차 검증을 사용한 평가
이런 대안으로 한가지가 교차 검증 기능을 사용하는 방법이 있다. 다음은 K-fold cross- validation을 수행하는 코드인데 훈련세트를 fold라 불리는 10개의 subset으로 무작위로 분할한다. 그런 현재모델(결정 트리 모델)을 10번 훈련하고 평가하는데, 매번 다른 fold를 선택해 평가에 사용하고 나머지 9개 fold는 훈련에 사용된다. 10개의 평가 점수가 담긴 배열이 결과에 담기는데 효용함수의 기대값이 나온다. 그래서 MSE의 반댓값(음수값)을 계산하는 neg_mean_squared_error함수를 사용한다. 그래서 제곱근을 계산하기 전에 -scores로 부호를 바꿨다.
|
1 2 3 4 5 6 7 8 9 10 11 |
#교차검증을 사용한 평가 scores = cross_val_score(tree_reg,housing_prepared,housing_labels, scoring="neg_mean_squared_error",cv=10) tree_rmse_scores = np.sqrt(-scores) def display_scores(scores): print("Scores:",scores) print("Mean:",scores.mean()) print("Standard deviation:",scores.std()) print(display_scores(tree_rmse_scores)) |
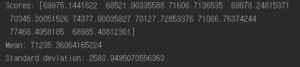
선형 회귀 모델보다 좋아 보이지 않는다. 비교를 위해 선형 회귀 모델의 점수를 계산한다.
|
1 2 3 4 5 |
#선형회귀 모델 점수계산 lin_scores = cross_val_score(lin_reg,housing_prepared,housing_labels, scoring="neg_mean_squared_error",cv=10) lin_rmse_scores = np.sqrt(-lin_scores) print(display_scores(lin_rmse_scores)) |

같은 방법으로 비교해본 결과 결정트리모델이 선형 회귀 모델보다 좋지 않음을 알수 있다. 마지막으로 RandomForestRegressor model을 시도해본다. 이 model은 특성을 무작위로 선택해서 많은 결정 트리를 만들고 그 예측을 평균 내는 방식으로 작동한다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#RandomForestRegressor forest_reg = RandomForestRegressor() forest_reg.fit(housing_prepared,housing_labels) forest_score = cross_val_score(forest_reg,housing_prepared,housing_labels, scoring="neg_mean_squared_error",cv=10) forest_rmse_scores = np.sqrt(-forest_score) print(display_scores(forest_rmse_scores)) forest_predictions = forest_reg.predict(housing_prepared) forest_mse = mean_squared_error(housing_labels,forest_predictions) forest_rmse = np.sqrt(forest_mse) print("훈련세트 점수: " + str(forest_rmse)) |

훨씬 성능은 개선됐으나, 훈련세에 대한 점수가 검증 세트에 대한 점수보다 훨씬 낮으므로 이 model도 여전히 훈련세트에 과대적합되어 있다. 이를 해결할 수 있는 방법으로 1. 모델을 간단히 한다. 2. 규제를 둔다. 3. 더 많은 훈련 데이터를 모은다.
그러나 이 모델로 더 깊이 들어가기전에 여러 종류의 머신러닝 알고리즘으로 많은 시간을 들이지 않으면서 적절히 시도해봐야 한다. 가능성 있는 2-5개 정도의 model을 선정하는 것이 목적이다.
모델 세부 튜닝
가능성 있는 모델드를 추렸다고 가정하고 세부 튜닝하는 몇가지 방법에 대해 알아본다.
그리드탐색
가장 단순한 방법으로 노가다로 최적의 하이퍼파라미터의 조합을 찾는 것이 있다. 노가다를 대신 뛰어주는 GridSearchCV 가 있다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#model 세부 튜닝 #그리드탐색 param_grid = [ {'n_estimators': [3,10,30], 'max_features': [2,4,6,8]}, {'bootstrap': [False], 'n_estimators': [3,10], 'max_features': [2,3,4]}, ] grid_search = GridSearchCV(forest_reg, param_grid, cv=5, scoring='neg_mean_squared_error', return_train_score=True) grid_search.fit(housing_prepared,housing_labels) print(grid_search.best_params_) cvres = grid_search.cv_results_ for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]): print(np.sqrt(-mean_score), params) |
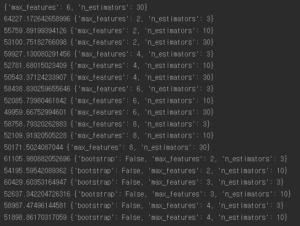
max_features 하이퍼파라미터가 6, n_estimators 하이퍼파라미터가 30일때 최적의 솔루션이다.
랜덤 탐색
RandomizedSearchCV를 사용하는 방식인데, 위 처럼 작은 공간에서 문제없지만 하이퍼 파라미터의 탐색 공간이 커지면 시간이 오래 걸리는 등 단점이 발생한다. 말그대로 랜덤으로 탐색하는 기법이다.
앙상블 방법
(결정 트리의 앙상블인 랜덤 포레스트가 결정 트리 하나보다 더 성능이 좋은 것처럼) 모델의 그룹이 최상의 단일 모델보다 더 나은 성능을 발휘할 때가 많다.
최상의 모델과 오차 분석
|
1 2 3 4 5 6 7 8 9 10 |
#최상의 모델과 오차분석 feature_importances = grid_search.best_estimator_.feature_importances_ #print(feature_importances) #중요도 다음 그에 대응하는 특성이름 표시 extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"] #속성추가 cat_one_hot_attribs = list(encoder.classes_) attributes = num_attribs + extra_attribs + cat_one_hot_attribs sorted(zip(feature_importances,attributes), reverse=True) |
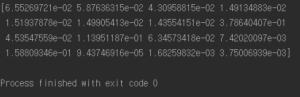
우리가 지금까지 본 model 중에 RandomForestRegressor model이 지금 최상의 모델이다. 최상의 모델을 분석하면 좋은 정보를 많이 얻는 경우가 있는데, 예를 들어 정확한 예측을 만들기 위한 각 특성의 상대적인 중요도를 알려준다.
테스트 세트로 시스템 평가하기
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#테스트 세트로 시스템 평가하기 final_model = grid_search.best_estimator_ X_test = strat_test_set.drop("median_house_value", axis=1) y_test = strat_test_set["median_house_value"].copy() X_test_prepared = full_pipeline.transform(X_test) final_predictions = final_model.predict(X_test_prepared) final_mse = mean_squared_error(y_test, final_predictions) final_rmse = np.sqrt(final_mse) print(final_rmse) |
![]()
주의 : 테스트세트는 한번만 돌려보며 (학습을 하기 때문) , 이후 건드리지 않는다.
우리가 만든 final_model 로 테스트세트로 평가한다.
론칭 모니터링 시스템 유지보수
제품시스템에 적용하기 위한 준비를 해야한다. 입력데이터 소스를 우리 시스템에 연결하고 테스트 코드를 작성해야한다. 일정 간격으로 시스템의 실시간 성능을 체크하고 성능이 떨어졌을 때 알람을 통지할 수 있는 모니터링 코드를 작성할 수 있으며, 새로운 데이터를 사용해 주기적으로 훈련시키지 않으면 데이터가 오래됨에 따라 모델도 함께 낙후되는 것이 일반적이다.
References : Hands-On Machine Learning with Scikit-Learn & TensorFlow