2장: 머신러닝프로젝트 처음부터 끝까지 (p.67)
개요 :이 장에서는 부동산 회사에 막 고용된 데이터 과학자라고 가정하고 예제 프로젝트의 처음부터 끝까지 진행하는 것이다. 실제 1990년 캘리포니아 인구조사 데이터를 기반으로 하여 캘리포니아 주택 가격 모델을 만드는 것이다.
1.housing Data의 형태
사용에 편의를 위해 csv file을 pandas로 다루기 쉬운 Dataframe형태로 바꾸었다.
|
1 |
housing = pd.read_csv('housing.csv') |

(20640, 10) dataset 즉, 10개의 특성을 가지는 20,640개의 data이다. total_bedrooms 부분이 20,433개를 제외한 나머지 207개는 NULL값(아무것도 아닌 값) 임을 알 수 있다.
첫 다섯행의 data 출력
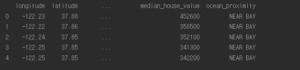
데이터 특성의 마지막을 보면 ocean_proximity 특성은 다른 숫자형 shape과 다르게 object임을 볼 수 있는데 첫 행의 다섯줄을 보면 NEAR BAY가 반복되는 것을 볼 수 있다. 이 특성은 아마 범주형일 것으로 추측된다.
|
1 |
print(housing["ocean_proximity"].value_counts()) |
어떤 범주가 있고 그 범주마다 몇 개가 있는지 value_counts() 메서드로 확인한다.

다른필드도 요약하여 출력해본다.
|
1 |
print(housing.describe()) |

이와 같은 계산은 아까 전 NULL 값으로 처리된 207개의 total_bedrooms는 포함되지 않는다.
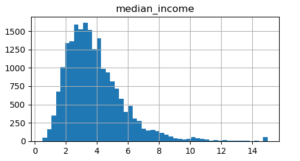
이제 데이터의 형태를 빠르게 검토하기 위해 히스토그램으로 그려본다.
|
1 2 |
housing.hist(bins=50, figsize=(20,15)) plt.show() |

몇 가지 확인 사항으로
- median_income이 달러로 표현되어 있지 않은 것 같다.
- median_house_value 와 housing_median_age 의 그래프 끝을 보아 심하게 올라가 있는 형태를 띄고 있는데 이것은 최댓값과 최솟값을 한정하여 몰빵? 되어있는 형태일 수 있다. (실제로 이 데이터는 그러함) median_house_value 는 정답label로 사용되기 때문에 학습할 때 문제가 될 수 있다. 만약 이 값이 필요하게 되면 정확한 레이블을 구하거나, 아니면 제거를 한다.
- 특성들의 스케일이 서로 많이 다르다.
- 몇몇개의 히스토그램 분포를 보면 꼬리쪽에 분포가 되어있는 것을 볼 수 있는데 이는 머신러닝 알고리즘에서 패턴을 찾아내기 어렵게 만든다. > 차후 종모양의 분포가 되도록 변형한다.
2.Test Dataset making
간단한 data 섞기
|
1 2 3 4 5 6 7 8 9 |
def split_train_test(data, test_ratio): shuffled_indices = np.random.permutation(len(data)) test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[ :test_set_size] train_indices = shuffled_indices[test_set_size: ] return data.iloc[train_indices], data.iloc[test_indices] train_set, test_set = split_train_test(housing,0.2) print("train 개수: "+ str(len(train_set)) + "\ttest 개수: "+str(len(test_set))) |
![]()
iloc 함수는 2차원배열 index 입력 값을 받아 해당위치 데이터를 보여주는 함수이다.
이런 코드는 반복할때 마다 dataset이 새롭게 shuffle 되므로 반복하면 전체 데이터셋을 보는 셈이므로 이런 상황은 피해야 한다. 계속 똑같은 shuffle 값이 나오게 해야된다는 말인데 난수 초깃값을 (seed value) 설정하거나 처음 shuffle한 값을 저장해서 사용하는 방법이 있다. 하지만 test dataset은 그대로 두고 train dataset을 업데이트하며 학습을 해야 하는데, test dataset이 같이 섞이게 되며 문제가 발생한다. 일반적으로 이를 해결하는 방법은 샘플의 식별자는 고유하기 때문에 이 해시 값을 계산하여 끝자리(마지막 바이트 값은 256을 가질 수 있다) 값이 51 보다 작거나 같은 샘플만 테스트 세트로 보내게 할 수 있다. (51 값이 20% 정도이기 때문) .
http://mwultong.blogspot.com/2006/06/qna-zip-rar-crc32-crc-crc.html
(위 주소는 고유식별자 해시 값을 구하는 방법인 csc32 설명이 잘 된 사이트)
|
1 2 3 4 5 6 7 |
def test_set_check(identifier, test_ratio): return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32 def split_train_test_by_id(data, test_ratio, id_column): ids = data[id_column] in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio)) return data.loc[~in_test_set], data.loc[in_test_set] |
하지만 주택 dataset 에는 식별자 컬럼이 없어서 행의 index를 ID로 사용한다. 이렇게 복잡한 함수 구현은 한번으로 족하고 사이킷런에서 이런 함수들을 많이 제공한다.
|
1 |
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42) |
위의 샘플리은 순수한 무작위 샘플링이다. dataset이 충분히 크다면 이는 괜찮지만, 그렇지 않으면 샘플링 편향이 생길 가능성이 커진다. 여기서 계층적 샘플링(stratified sampling)을 사용할 수 있는데 이는 모비율 만큼 표본비율도 같이 해주는 것이다. 예를 들어 인구조사를 할 때 알려진 총 인구 중 여성이 51.3% 남성이 48.7%이라면 1000명을 샘플링하면 여성 513, 남성487명을 뽑는 것이다.
전문가가 중간소득이 예측하는데 아주 중요한 변수로 작용한다고 알려주었다 가정하자. 이 경우 test set이 전체 dataset에 있는 여러 소득 카테고리를 잘 대표해야한다. 중간소득을 discrete하게 만들어주는 작업을 하겠다.
계층별로 dataset에 충분한 샘플 수가 있어야 한다. 그렇지 않으면 계층의 중요도를 추정하는 데 편향이 발생할 것이다. 너무 많은 계층으로 나누면 안되고, 각 계층이 충분히 커야함을 의미, 다음 코드는 중간소득을 1.5로 나눠준다.
|
1 2 3 |
#중간소득을 discrete하게 만들어주는 작업 housing["income_cat"] = np.ceil(housing["median_income"] / 1.5) housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True) |
ceil 은 반올림함수이고 where은 index 함수이다.

소득 카테고리를 기반으로 계층 샘플링을 할 준비가 되었다.
|
1 2 3 4 5 6 |
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index] print(housing["income_cat"].value_counts() / len(housing)) |
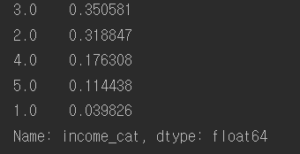
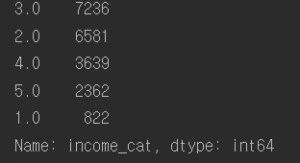
왼 : 전체 주택 dataset에서 소득 카테고리의 비율
오 : housing[income_cat] 의 value count
비교

무작위 샘플링보다 계층 샘플링의 정확도가 더 높은 것을 확인할 수 있다.
|
1 2 3 |
#income_cat 특성삭제 데이터를 원상태로 되돌림 for set_ in (strat_train_set, strat_test_set): set_.drop("income_cat", axis=1, inplace=True) |
다음 포스팅에서 더
전체 code :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
from zlib import crc32 from sklearn.model_selection import train_test_split import os import tarfile from six.moves import urllib import pandas as pd import csv import matplotlib.pyplot as plt import numpy as np from sklearn.model_selection import StratifiedShuffleSplit #데이터 읽어들이기 # df = pd.read_csv('housing.csv',names=['longitude','latitude','housing_median_age','total_rooms', # 'total_bedrooms','population','households','median_income', # 'median_house_value','ocean_proximity']) housing = pd.read_csv('housing.csv') # 데이터 형태 훓어보기 #print(housing.head()) #print(housing.info()) #print(housing["ocean_proximity"].value_counts()) #print(housing.describe()) #housing.hist(bins=50, figsize=(20,15)) #plt.show() # 테스트 세트 만들기 #def split_train_test(data, test_ratio): # shuffled_indices = np.random.permutation(len(data)) # test_set_size = int(len(data) * test_ratio) # test_indices = shuffled_indices[ :test_set_size] # train_indices = shuffled_indices[test_set_size: ] # return data.iloc[train_indices], data.iloc[test_indices] #train_set, test_set = split_train_test(housing,0.2) #print("train 개수: "+ str(len(train_set)) + "\ttest 개수: "+str(len(test_set))) # 해시값을 이용한 테스트 세트 중복피하기 #def test_set_check(identifier, test_ratio): # return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32 #def split_train_test_by_id(data, test_ratio, id_column): # ids = data[id_column] # in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio)) # return data.loc[~in_test_set], data.loc[in_test_set] #housing_with_id = housing.reset_index() # 'index' 열이 추가된 데이터 프레임이 반환된다. #train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index") #housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"] #train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id") #sklearn 사용하여 나누기 train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42) #중간소득을 discrete하게 만들어주는 작업 housing["income_cat"] = np.ceil(housing["median_income"] / 1.5) housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True) #housing["income_cat"].hist(bins=50, figsize=(20,15)) #plt.show() #카테고리 기반 계층 샘플링 split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index] #print(housing["income_cat"].value_counts() / len(housing)) #print(housing["income_cat"].value_counts()) #income_cat 특성삭제 데이터를 원상태로 되돌림 for set_ in (strat_train_set, strat_test_set): set_.drop("income_cat", axis=1, inplace=True) |
References : Hands-On Machine Learning with Scikit-Learn & TensorFlow