*Weight Initialization에 관해(잘못이해한 지식)
-
발생하는 문제
우리는 신경망을 학습시킬 때 제대로 학습이 이루어지지 않거나(under fitting) 혹은 이루어진 후에 실생활에 잘 들어먹지 않을 때가 발생한다. (over fitting)

under fitting은 데이터를 표현함에 있어서 너무 단순하게 표현하여 학습하는 데이터에 대한 정확도가 떨어지는 것을 의미한다. (bias와 관계)
over fitting은 데이터를 각각에 너무 맞춰 표현하여 학습 시에는 매우 높은 정확도를 보이나 실제 테스트 데이터와 비교할 때는 정확도가 떨어지는 현상을 의미한다. (variance와 관계)

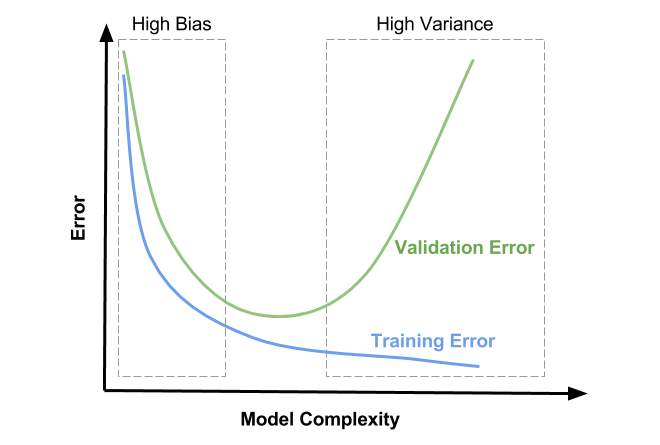
낮은 분산과 높은 편향의 경우 : 밀집도는 좋지만 정확성은 떨어진다.(under fitting)
낮은 분산과 낮은 편향의 경우 : 이것이 우리가 원하는 신경망학습
높은 분산과 높은 편향의 경우 : 제일 ㅈ 같은 경우
높은 분산과 낮은 편향의 경우 : 정확성은 있으나 데이터의 퍼짐이 크다.(over fitting)
잘못이해한 부분 —- (밑에 부터 하지만 정의는 맞음;)
직관적인이해
Error(X) = noise(X) + bias(X) + variance(X)
X에 대한 에러의 구성은 다음과 같으며
noise(X) : 어쩔 수 없는 error로 우리가 control하기 어려운 부분이다. 이해하기 쉽게 잘못 기입된 데이터 수치 등
bias(X) : 데이터 내에 모든 정보를 잘 훓어보지 않고 잘못된 정보를 학습하고 있는 경향
variance(X) : 너무 광범위하게 다 학습하여서 굳이 필요 없는 것들까지 학습하는 경향
그 중 우리는 noise를 제외한 bias와 variance를 조정할 수 있다.
수학적 이해

f(x) : 정답 값을 뜻하며 , 예로 2x + 4 = f(x) x가 1일때, f(x) = 7
f^hat (x) : 찍어본 예측 값이며, 여러번 찍어보면 위 처럼 예측 값을 파랑 점 여러개로 가질 수 있다.
E[f^hat(x)] = 여러 예측 값들에 대한 기댓값이며 평균적인 의미로 사용한다.
 = Bias^2 , 즉 편향(의제곱) 을 뜻하며, (예측값들의 기댓값 – 정답값) 이다. 제곱을 한 이유는 음의 값으로 인한 계산의 어려움을 피하고자 한 것이다. 즉 우리가 찍어본 예측 값들을 대표하는 기대값 하나가 정답 점과 얼마나 떨어져 있는지를 알려준다.
= Bias^2 , 즉 편향(의제곱) 을 뜻하며, (예측값들의 기댓값 – 정답값) 이다. 제곱을 한 이유는 음의 값으로 인한 계산의 어려움을 피하고자 한 것이다. 즉 우리가 찍어본 예측 값들을 대표하는 기대값 하나가 정답 점과 얼마나 떨어져 있는지를 알려준다.
 =Variance 분산으로 , (예측 값 – 기댓값)의 제곱으로 표현한다.
=Variance 분산으로 , (예측 값 – 기댓값)의 제곱으로 표현한다.
그리고 마지막으로 정체를 모르는 어쩔 수 없는 error ![]() 가 존재한다.
가 존재한다.
예측 값 한개를 x 라 하면 Error(x) 에 대한 식은
전개할 수 있다. 실제로 ![]() 값은 알지 못하며 확률적으로 움직이기 때문에 Error(x) 또한 확률적으로 움직이게 된다. 그래서
값은 알지 못하며 확률적으로 움직이기 때문에 Error(x) 또한 확률적으로 움직이게 된다. 그래서 ![]() 값을 0으로 고정하여 가정한다.
값을 0으로 고정하여 가정한다.