M.L (p.196)
AdaGrad
신경망 학습에서 학습을 할 때, 학습률을 너무 작게 주면 거의 움직이지 않고, 크게 주면 발산해버리는 문제가 발생한다. 얼만큼 학습률을 주어야 적절한 학습을 할 수 있을 것인지에 대한 물음이 생기는데 이에 대한 효과적인 기술로 ‘학습률 감소 (learning rate decay)’가 있다. 학습을 진행하면서 학습률을 점차 줄여가는 방법이다. 학습률을 서서히 낮추는 가장 간단한 방법은 매개변수 전체의 학습률 값을 일괄적으로 낮추는 것이다. 이를 더욱 발전시킨 것이 AdaGrad 이다. AdaGrad의 핵심은 각각의 매개변수에 맞춤형 값을 만들어준다.

![]() AdaGrad 식
AdaGrad 식
식을 보면 손실함수의 기울기를 제곱하여 h라는 변수에 값을 갱신하는데 ![]() 기호는 각각 배열위치에 해당하는 값끼리 곱하는 것을 의미한다.
기호는 각각 배열위치에 해당하는 값끼리 곱하는 것을 의미한다.
즉 (2,2) ![]() (3,5) = (6,10)
(3,5) = (6,10)
제곱을 해주는 이유는 ![]() 에서 양의 값으로 나타내기 위해 해주는 작업이며 결국 손실함수기울기가 갱신되며 h에 더해가며 쌓이고
에서 양의 값으로 나타내기 위해 해주는 작업이며 결국 손실함수기울기가 갱신되며 h에 더해가며 쌓이고 ![]() 이값이커질수록
이값이커질수록
변화되는 양은 적어진다. 또한 각각의 값을 제곱해 루트화 시킴으로써 각각의 손실함수기울기에 의해 변화되며 손실함수 기울기가 컸다면 변화는 작게되며 손실함수의 기울기가 작았다면 큰 기울기에 비해 변화가 크다.
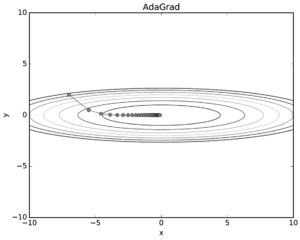 그림을 보면 y축 방향은 기울기가 커서 처음에는 크게 움직이지만, 그 값에 비례해 갱신 정도도 큰 폭으로 작아지도록 조정된다.
그림을 보면 y축 방향은 기울기가 커서 처음에는 크게 움직이지만, 그 값에 비례해 갱신 정도도 큰 폭으로 작아지도록 조정된다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
class AdaGrad: def __init__(self,lr=0.01): self.lr = lr self.h = None def update(self,params,grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) |
코드로 구현한 것이며 마지막에 1e-7 (아주 작은 값) 을 넣어준 것은 0으로 나누는 사태를 막아준다.
추가 Adam
Momentum 과 AdaGrad 를 융합해보자는 idea에서 출발한 기법이다. 자세한 것은 추후에 업데이트
